CV论文精炼
最后更新时间:
文章总字数:
页面浏览: 加载中...
Low-Level
这篇博客是无限长的,随着阅读论文数量的增多,将会越来越长。这篇博客的目的与定位就是简介描述的,精简提炼所读论文中的创新点,贡献,个人认为的不足。无详解,只是一个摘要的作用。有时候,我会把某篇论文的详解做出来。当然,看心情和时间吧。能够提炼出要点,说明这篇文章的思想才算是完全吸收。做精炼论文是好习惯,要养成。
[TOC]
Low-Light Image Enhancement
2024 CodeEnhance: A Codebook-Driven Approach for Low-Light Image Enhancement
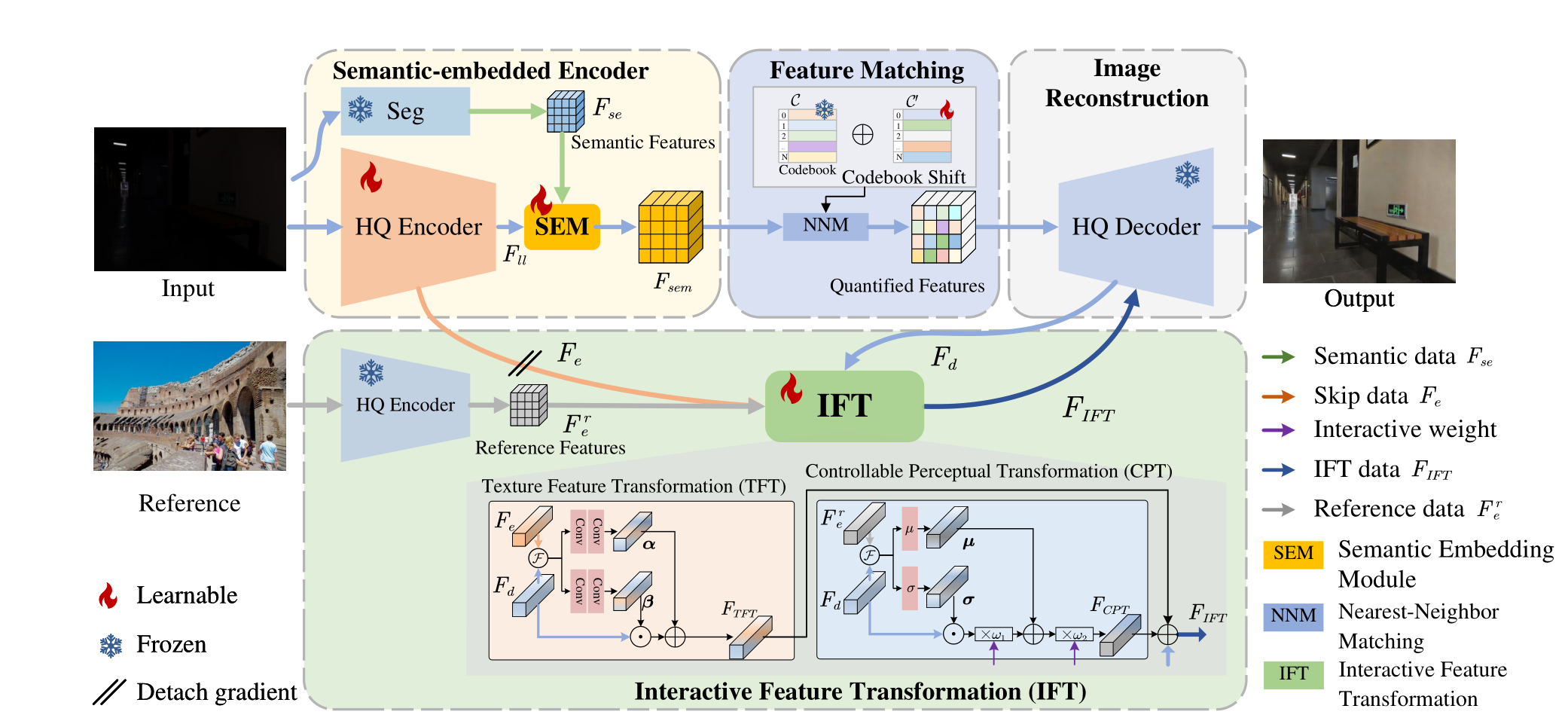
贡献
- 利用
codebook从High-Quality图像中学习先验。 - 在
Unet编码器端并行设计预训练的语义信息提取网络SEE,在编码器末端设计一个语义信息融合模块SEM,将语义信息与图像特征融合。 - 因为
codebook学习的先验所用数据集和第二阶段训练所用数据集不同,设计了一个codebook偏移机制CS处理引入codebook产生的数据分布偏移问题。 - 在预训练的解码器末端附加一个特征转换模块
IFT。一方面,利用参考图像Reference丰富解码器High-Quality解码图像的信息,另一方面,在IFT内的CPT加入两个人为设计的以实现可控式图像提亮。
创新
很明显知道这篇低光的论文是基于
Towards Robust Blind Face Restoration with Codebook Lookup Transformer这篇文章的工作,所以创新是相对于Towards Robust Blind Face Restoration with Codebook Lookup Transformer的创新。我们可以把Towards Robust Blind Face Restoration with Codebook Lookup Transformer称为base work
- 在
encoder并行引入一个语义感知模块,与encoder通过一个语义融合模块融合。这个做法是借鉴了23年ICCV的一篇与语义分割结合的低光工作:Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement。 IFT源于base work的CPT。但是base work的CPT是将低质量图作为参考,而本文章是把ground-truth作为参考。- 发现
codebook两阶段输入的数据分布不一致,提出代码本数据偏移机制。这是较base work优秀的地方。
所以很明显,我们不应该是将别的领域的东西套过来到本领域去用,而是把自己领域的东西尽可能往别的领域靠、结合,才是更好的。要针对别的领域的工作,提出一个基于本领域的改进。
不足
- 极其依赖
ground-truth和reference。codebook的训练依赖high-quality图像进行重建不说,IFT需要一张正常光照的图作为参考。训练时期,IFT尚且可以。然而测试如果再依赖一张正常光照的图像作为reference,那就没有什么应用意义。虽然通过这种方式能够实现光照恢复动态化,但缺点也很明显。 - 解决
codebook的数据偏移问题过于粗糙,引入可学习的codebook shift增加了训练的困难。
2023 CVPR Learning a Simple Low-light Image Enhancer from Paired Low-light Instances
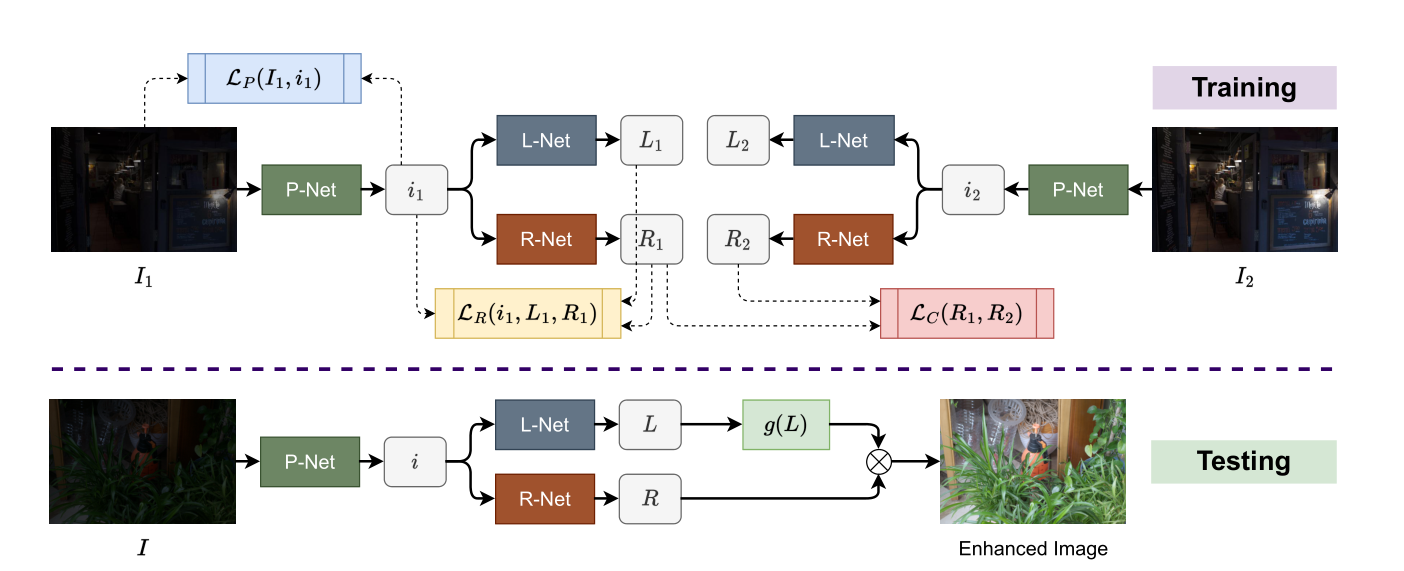
贡献
- 使用两张低光的图片,结合
Retinex理论,实现不需要额外设计手工先验的无监督低光增强。 - 在使用
Retinex分解前,使用一个映射网络有效增强分解准确率。
创新
- 将超分辨率中多图像辅助修复单图像的做法引入到低光照增强领域中,为多图像辅助修复单图像提供了低光照增强的做法。
不足
- 训练阶段,两张低光图经过
L-Net得到的结果并未充分利用。 - 这个工作更重要的意义在于,将多图像的信息辅助单图像的恢复。然而作者的做法是,多引入图片就设计一个新的,与待恢复图像相同的网络架构,即L-Net,R-Net和P-Net。倘若扩展到更多图像,不可能再同样为每一张新引入的图片设计一整套网络。因此这种做法限制了多图像的信息辅助单图像的恢复,局限于双图像。
- 推理阶段,
L-Net估计得到的L只进行一个指数变换,得到就作为提亮后的光照,这种做法能否优化? R-Net的输出R并未经过任何处理,是否影响了性能的上限?
2024 DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement
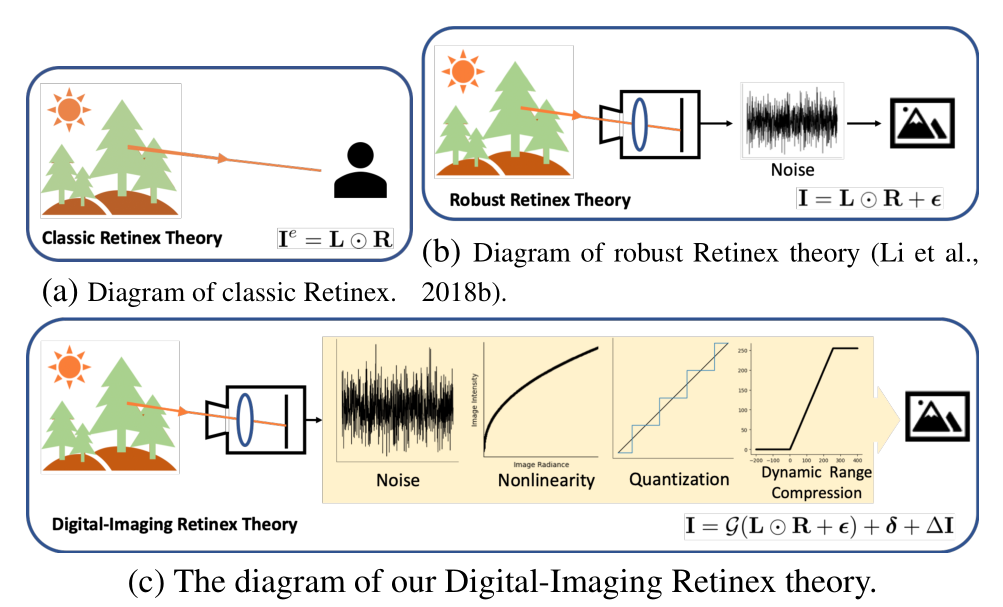
贡献
- 指出经典的
Retinex理论存在缺乏考虑噪声的问题,提出了一个新的适用于数码成像的Retinex理论DI-Retinex。 - 根据
DI-Retinex理论,重新规定了光照提亮的范式。范式中的偏置项即为经典Retinex理论未考虑到的缺陷。 - 为
DI-Retinex理论设计了两个损失,分别是将正常光照退化为低光图像的反向退化损失以及噪声的方差抑制损失。
创新
- 相对于传统的
Retinex理论以及改良版本的Retinex理论,提出的DI-Retinex理论考虑更加全面。
不足
(暂时未有)
2024 CVPR Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
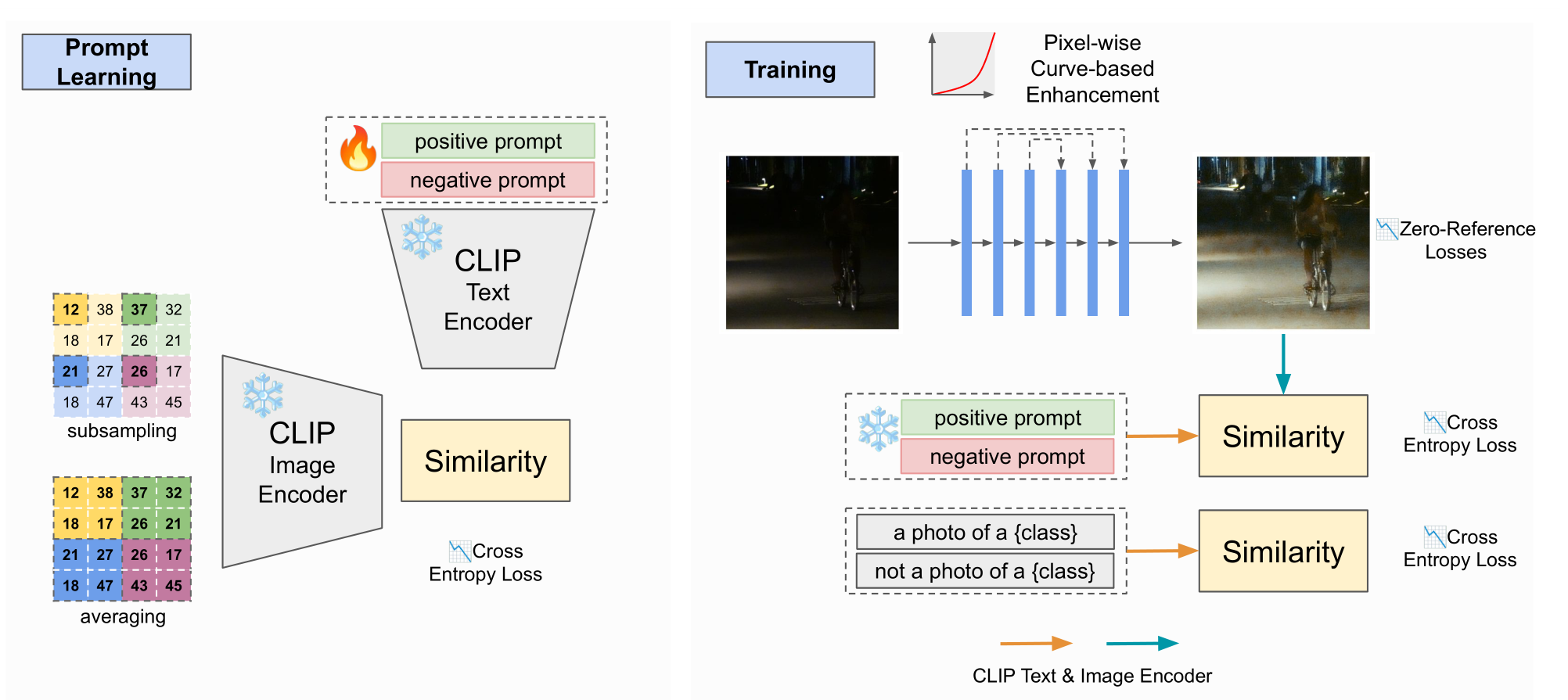
前身工作是
2023 ICCV Iterative Prompt Learning for Unsupervised Backlit Image Enhancement
存疑
- 在
prompt learning阶段要训练positive prompt和negative prompt,这两个prompt是怎么初始化的?形式是怎么样的? - 在
training阶段,使用曲线估计提亮后面的部分没看明白。
2024 GLARE: Low Light Image Enhancement via Generative Latent Feature based Codebook Retrieval
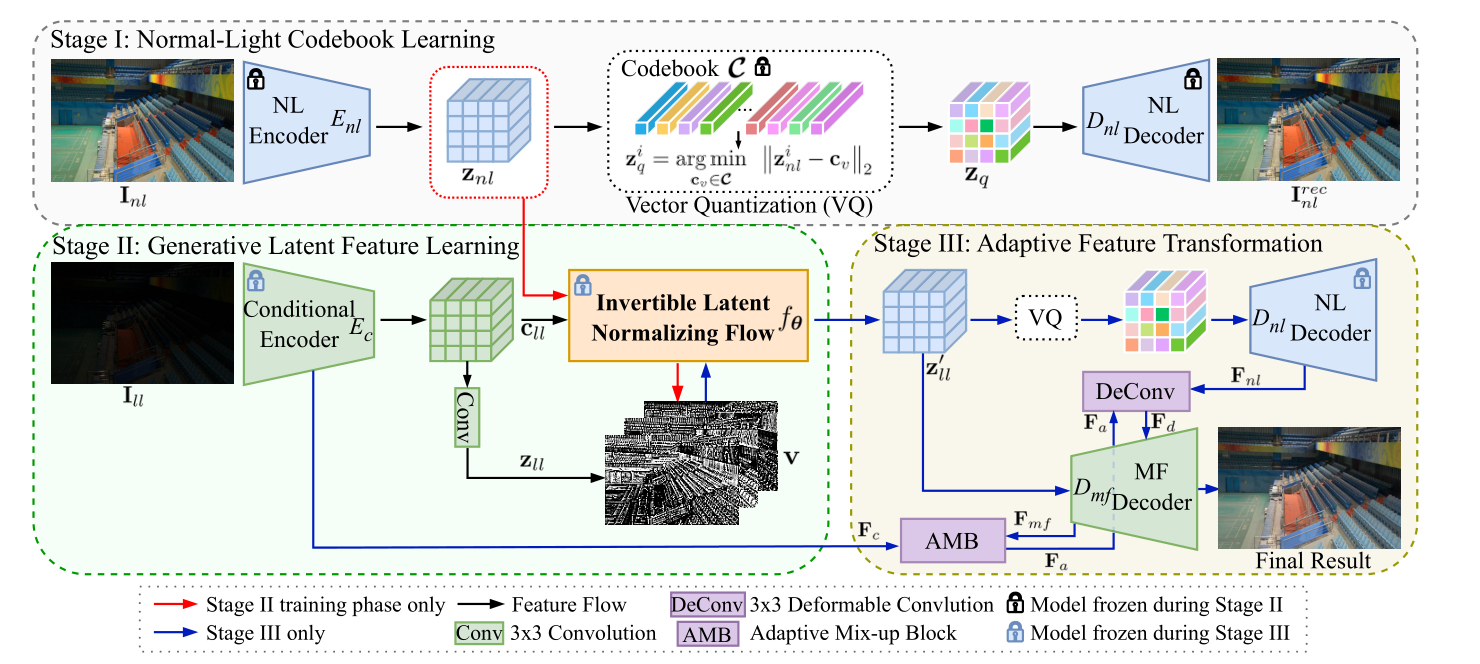
贡献
- 第一个将
codebook引入低光照图像增强领域的工作。将预训练的VQGAN进行微调以更适合低光照图像增强背景。 - 为了解决
codebook难题之阶段前后数据分布不一致,提出一个逆向潜特征正则流(Invertible Latent Normalizing Flow)的操作,将低光特征经过转换,逼近正常光照的特征,以更加适合codebook适用的数据分布。 - 为了解决
codebook难题之纹理缺失,提出一个双译码器架构实现将先前Encoder编码的特征与codebook检索出来的特征融合。
创新
- 第一篇将
codebook引入低光的工作。 - 逆向潜特征正则流(
Invertible Latent Normalizing Flow)是本文的亮点,实现了数据分布的近似转换,效率很高。 - 在双译码器端,使用一个特征适应转换模块通过调整参数实现
encoder流向decoder数据的控制,我的理解是和codeformer差不多。
不足
codebook的工作,都有泛化性相对不足的缺点。在推理阶段,codebook是在训练集上训练的,得到的是训练集的先验知识,在后续与测试集low-quality特征融合。因此需要从codebook得到知识后,需要有进一步优化操作。
2023 ICCV Implicit Neural Representation for Cooperative Low-light Image Enhancement
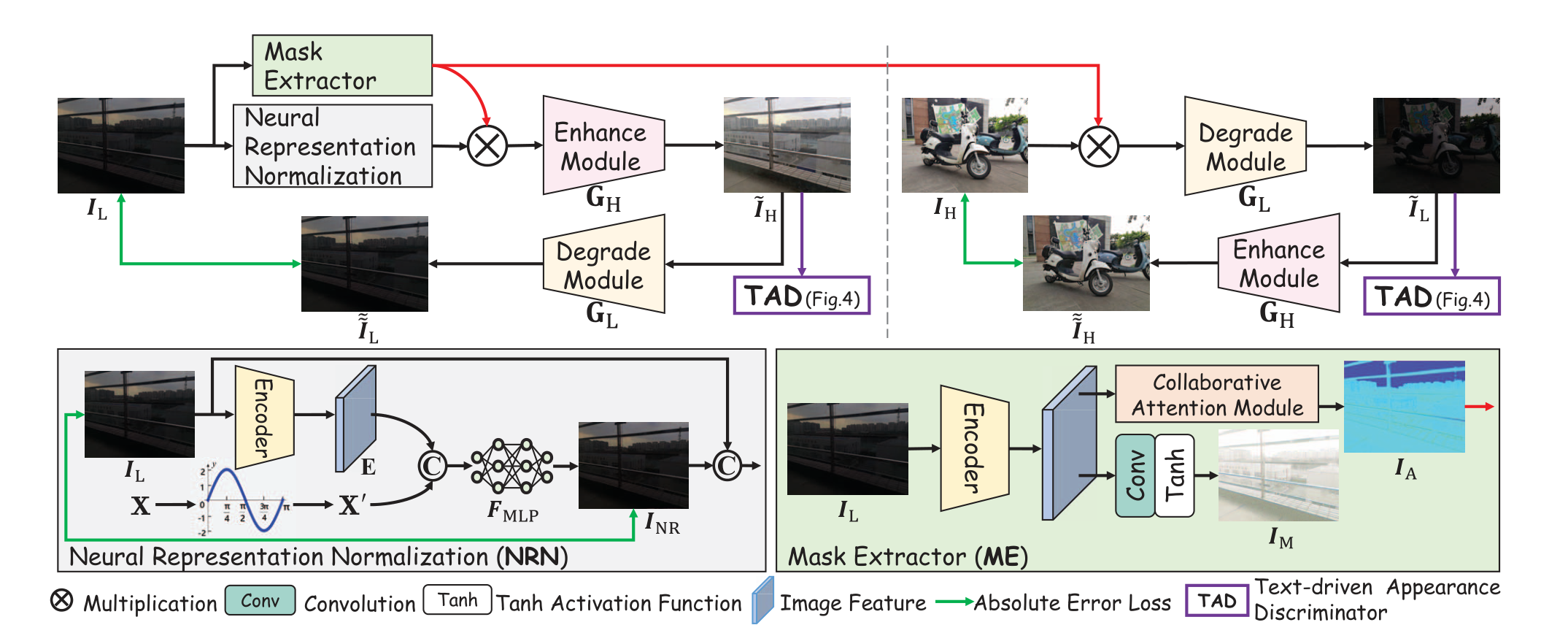
这次我们先只看这个工作的
NRN部分,也就是Neural Representation Normalization。
贡献
- 将隐式神经表征
Implicit Neural Representation第一次引入到低光照图像增强领域中。
创新
- 将隐式神经表征与低光背景很好地结合,并且解释了为何能实现去噪。
存疑
- 对隐式神经表征了解还不够多,应该往这个领域多研究研究。
Image Dehazing
2023 CVPR RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors
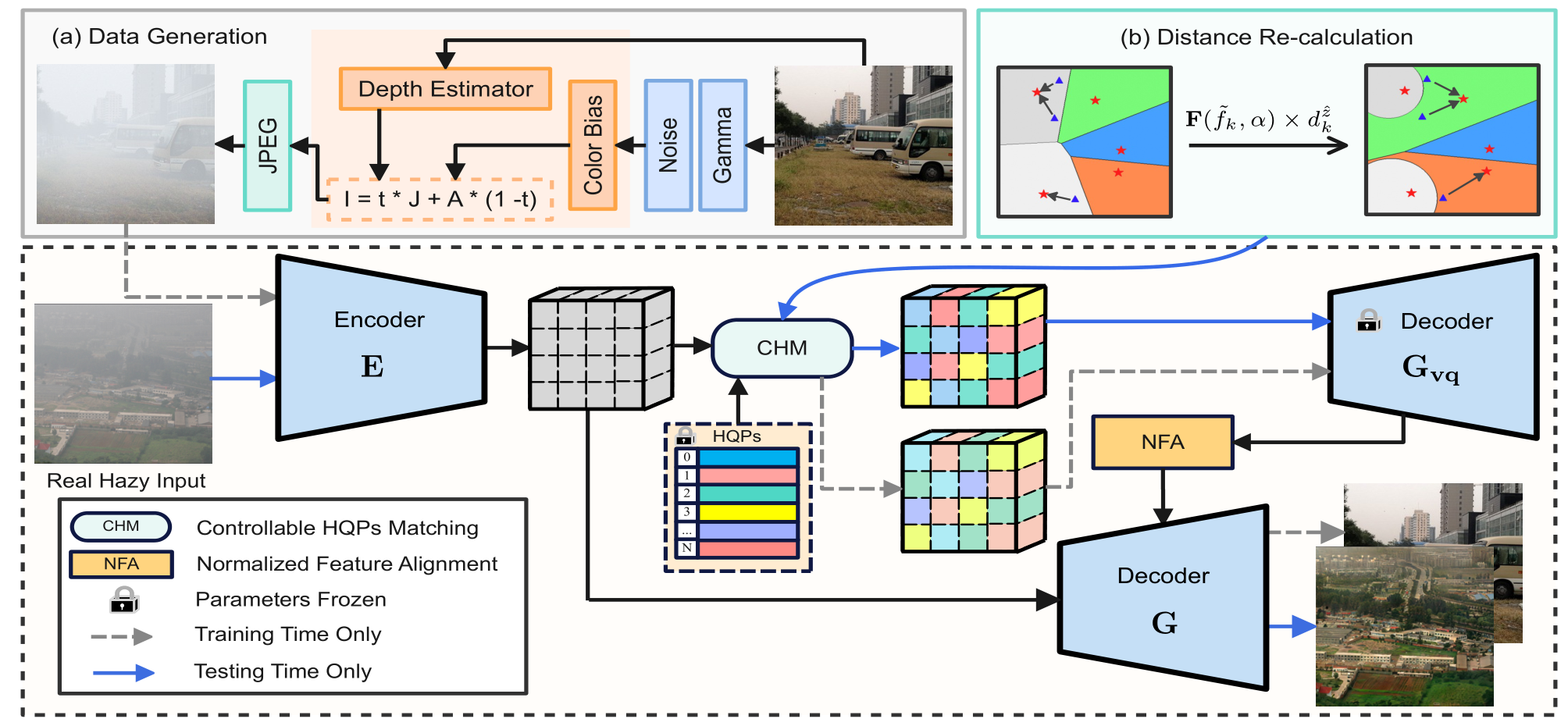
贡献
- 第一个将
codebook方法引入到去雾领域的工作。 - 设计了一个可控匹配机制
CHM替代最近邻匹配机制。具体来说,在最近邻匹配公式内的欧氏距离前乘以权重,增强匹配的效果。权重是一个自然指数,以系数a与f乘积为底。系数a通过最小化codebook特征与encoder输出特征的KL散度得到。系数f是codebook激活频率与encoder激活频率的差值(说实话论文中这个什么激活频率没交代是怎么得到的,没看明白,大概理解就是codebook与encoder的特征距离) - 设计一个双译码器,通过一个归一化特征匹配
NFA模块,将第一个译码器的输出与 encoder的输出进行特征融合。
创新
- 可控匹配机制
CHM改良了最近邻匹配机制,减轻数据分布偏差的问题。
不足
- 在可控匹配机制
CHM的实现上面,前面提到,通过乘以一个指数权重改良最近邻匹配,这个指数以两个系数乘积为底,第二个系数f,论文交代十分模糊,称为codebook激活频率差,我理解是两个数据分布的距离。在代码中也不详细,f通过一个预训练数据给出,预训练也不知道如何训练得到的。
Vision Prompt Learning
2024 Towards Effective Multiple-in-One Image Restoration: A Sequential and Prompt Learning Strategy
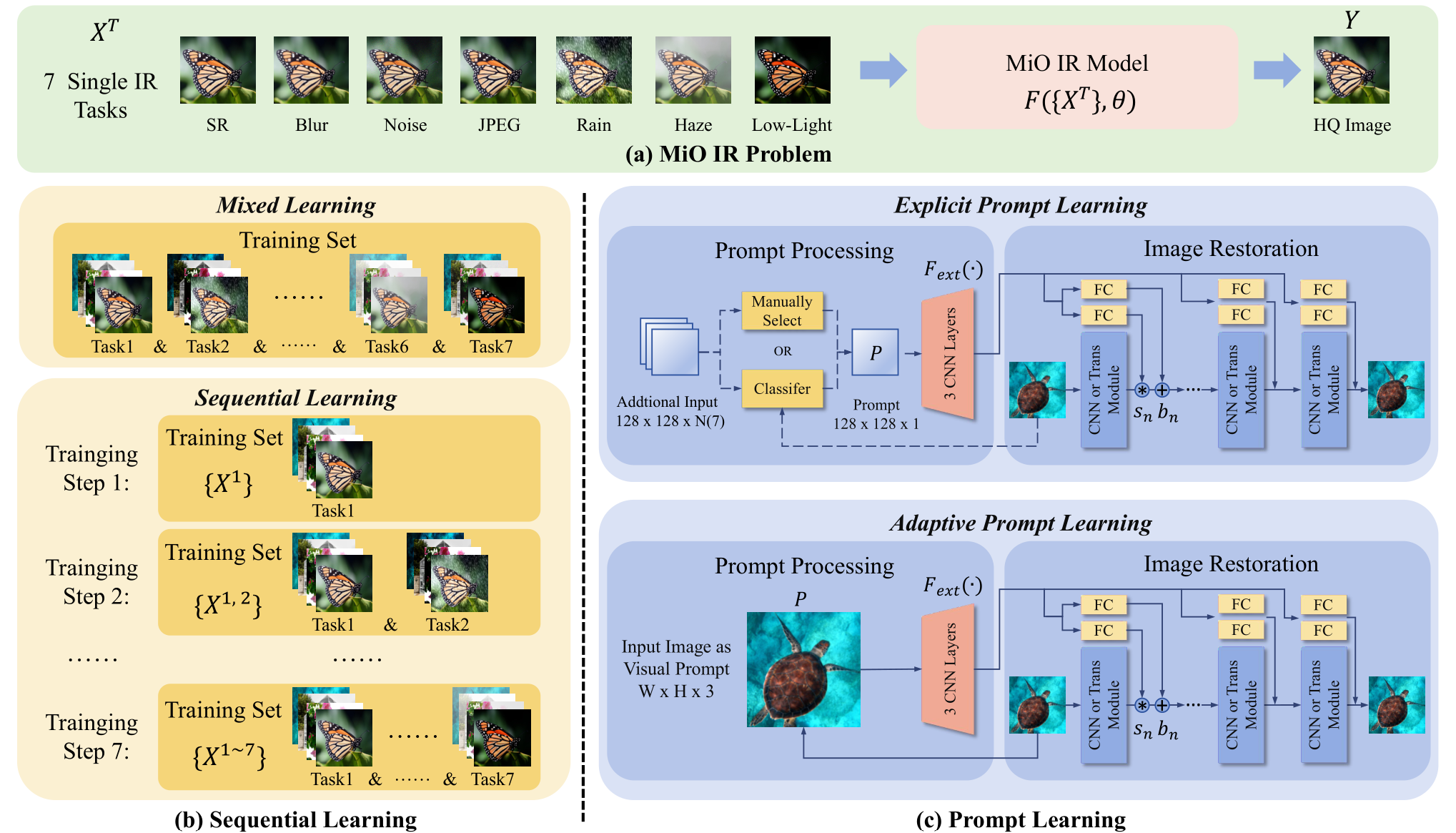
贡献
- 指出
all-in-one模型的问题:考虑的退化任务少;每一次训练只在一个特定的退化任务数据集上训练,有可能导致灾难性遗忘。提出序列学习,每次训练的数据,是上次训练的数据与新特定退化类型数据的叠加,有效应对灾难性遗忘。 - 使用两种极端的提示学习方法,帮助模型识别特定退化任务,分别是精确提示学习与自适应提示学习。
- 精确提示学习:通过预先训练提示,提示分类器,在下一阶段通过输入的退化图片筛选出适合的提示,引导特定退化任务的图像恢复。
- 自适应提示学习:通过输入的退化图片经过卷积处理得到提示信息,引导特定退化任务的恢复。
创新
- 第一次将序列学习引入到图像恢复领域。
不足
- 个人认为,自适应提示学习不能算作提示学习,更像是特征融合。
Blind Face Restoration
2022 NeurIPS Towards Robust Blind Face Restoration with Codebook Lookup Transformer
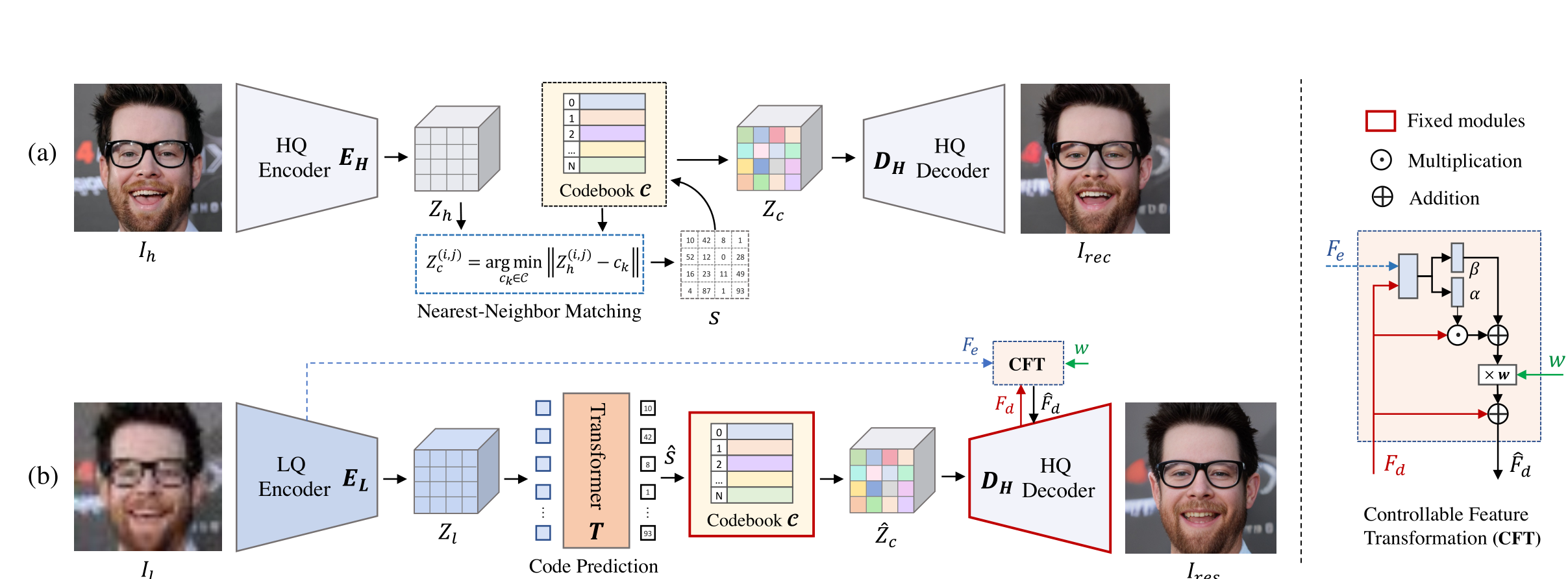
贡献
- 将
codebook引入到人脸修复领域中。 - 指出
codebook索引方式即最近邻特征匹配方法应用到图像恢复领域的不足在于,输入的Low-Quality图像因为各种类型的退化严重导致Low-Quality与codebook的数据分布严重不匹配,进而造成了codebook检索的困难。因此,为了能够更好地进行codebook的检索,使用Transformer进行codebook的检索,提高检索精确度。 - 如果仅仅将
codebook提取出来的特征进行解码,由于codebook是从其他数据集上训练得来的,因此解码得到的特征与当前数据集的GT会有很大差异,所以有必要将输入与codebook的特征进行融合,以得到一个质量更优于Low-Quality,数据分布更接近High-Quality的图片。进一步,引入一个可控的特征转换器CFT,通过一个人为设置的超参数w,实现Encoder到Decoder数据流的控制,即实现可控式的特征融合。
创新
- 将
codebook引入到人脸修复领域。 - 提出最近邻特征匹配在图像恢复的不足,为未来的工作提供了很好的指引。
- 设计了一个可控的特征融合器,进一步弥补了
codebook的不足。
不足
- 通过单一的
Transformer块叠加进行codebook索引,造成索引耗时长的问题。
2022 VQFR: Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder
Image Restoration
Super-Resolution
Image Derain
2024 CVPR Bidirectional Multi-Scale Implicit Neural Representations for Image Deraining
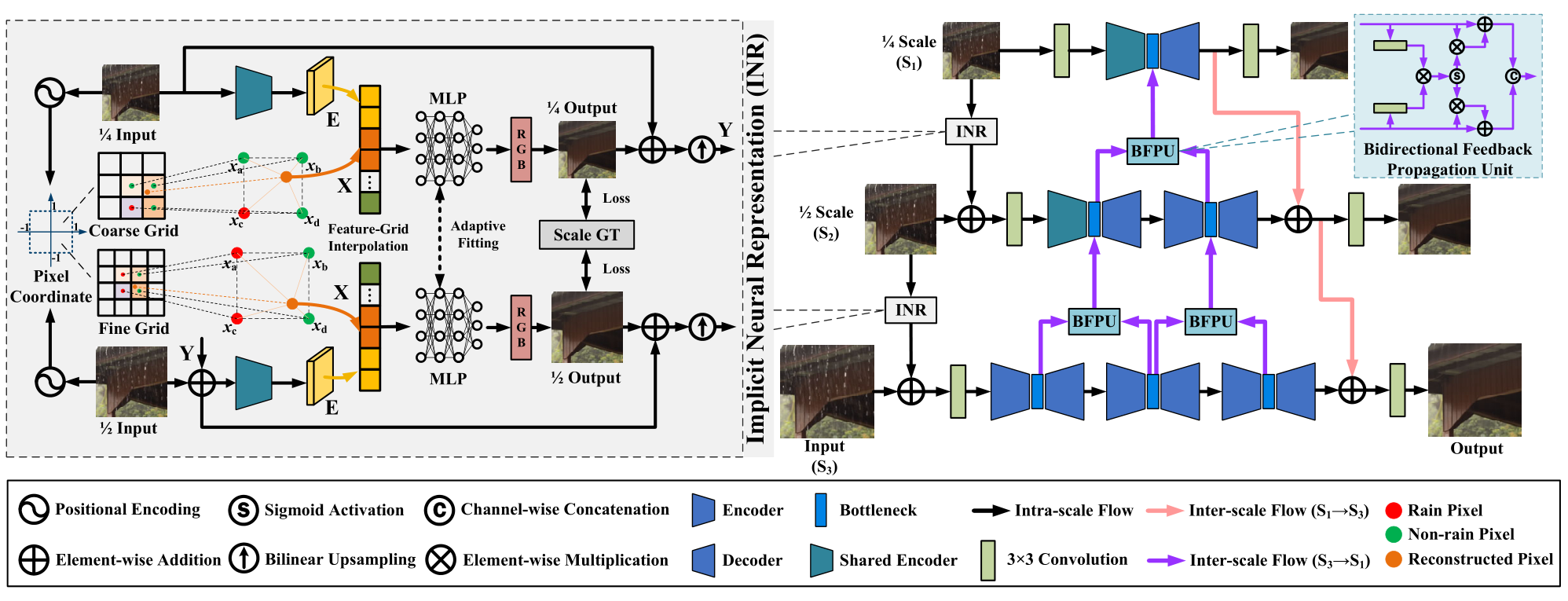
这里先主要研究前面的
Implicit Neural Representation部分。
贡献
- 将隐式神经表征第一次引入图像去雨领域中,以更好地帮助模型学习普遍雨纹退化特征进行退化的去除。
- 将隐式神经表征与多尺度网络结合,能够在多尺度信息流动中进行退化的去除。
创新
- 在每个尺度的网络前引入
Implicit Neural Representation去除雨纹,形成一个在尺度上的级联Implicit Neural Representation结构。
不足
(暂时未知)
High-Level
Implicit Neural Representation
打赏

