# 1. 资源
课件资料:https://github.com/stanford-cs336/spring2025-lectures
clone 下来后,将 var 目录移动到 trace-viewer 中的 public 目录内,将 images 目录也移动到 public 目录内,然后 cd trace-viewer,以此命令 npm install 和 npm run dev,到浏览器打开如下链接来看第一章的课件:
http://localhost:5173?trace=/var/traces/lecture_01.json
这个链接只是示例,localhost 后面的端口根据自己运行实际情况而定。不同的课程有对应的 json。
相关中文博客:https://www.cnblogs.com/apachecn/p/19577358
其他可能参考的资料:https://datawhaler.feishu.cn/wiki/SBGEw3kFfipFQbkStGocaFVHnSf
# 2. 为什么要学 Standford CS336?
- 理解大模型底层逻辑。
- 为你提供如何选择、处理数据,以及如何建模的直觉。
- 纠正资源至上心态,优化算法能最大化资源利用效率。精度 = 算法效率 x 资源投入。

# 3. 课程大纲

# 4.Tokenization 概览
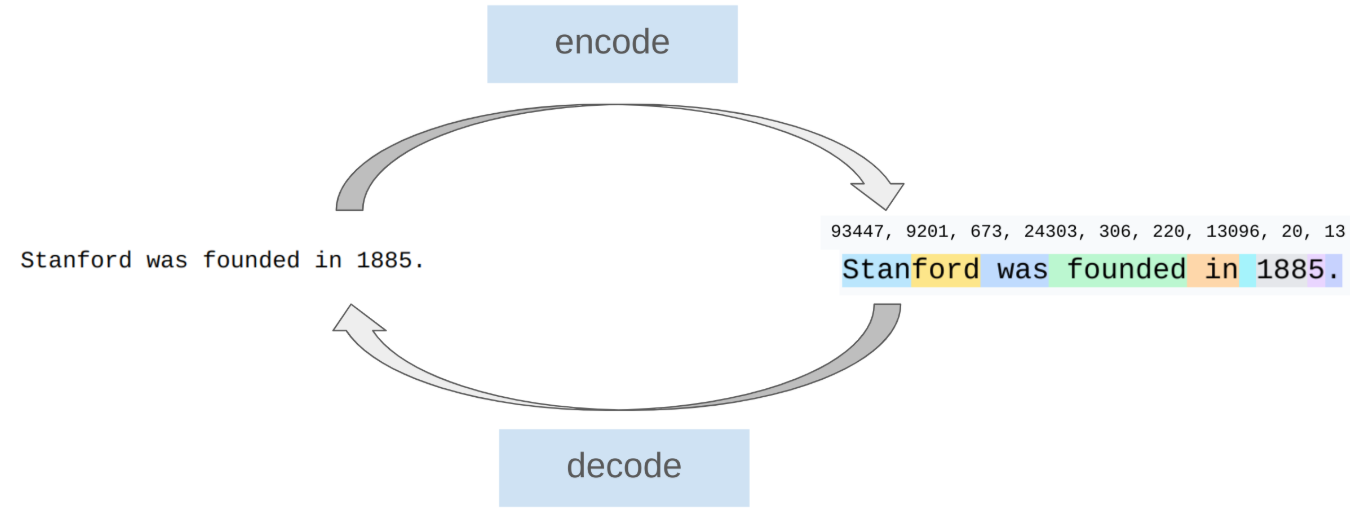
Tokenization 的作用是将字符串分割为若干片段,这些片段称为 token,并为这些片段逐个赋予一个数字,这个过程称为 Tokenization 的编码。而这些编码片段也可以通过解码得到原来的字符串。
课程将以 BPE(Byte-Pair Encoding)Tokenization 为例进行 tokenization 技术的讲解,并要求你在无 AI Tools 和少量 Pytorch API 调用的情况下实现一个 BPE。
另外可以提到也有无 Tokenization 技术,主要通过直接读取字节来实现语言建模。然而在现在的前沿模型中,Tokenization 技术已经十分常见,课程暂且不论无 Tokenization 的方法。
# 5. 最大化硬件效率
在训练的时候,加快训练速度,最大化硬件资源效率的一个 Trick 是,最大化 GPU 的利用率。
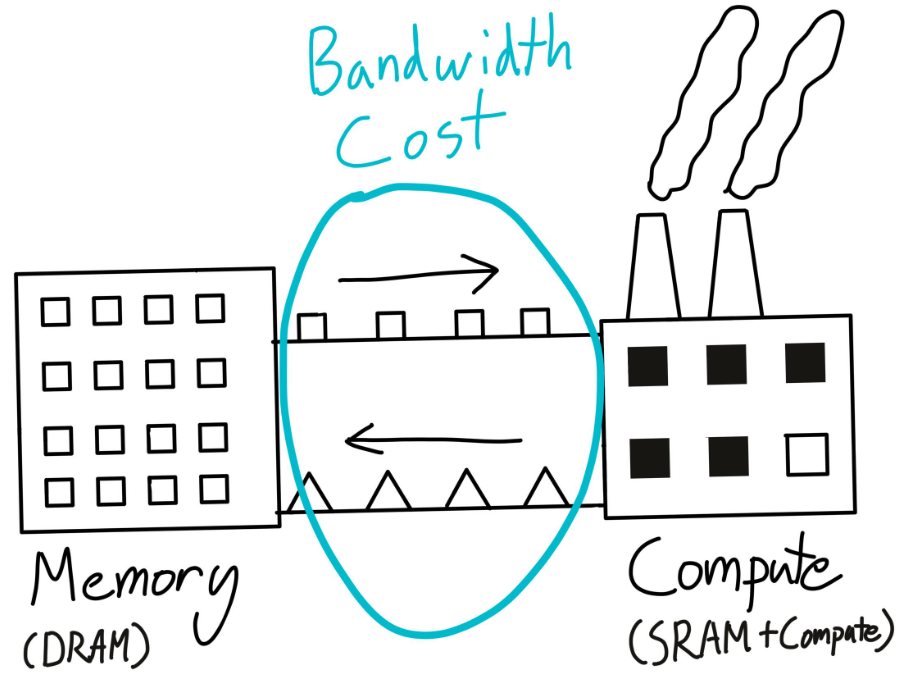
在训练模型的过程中,GPU 的作用是负责计算和模型训练,CPU 的职责是负责将模型参数、optimizer 参数以及其他超参从外存运到内存,从内存运到 GPU 中。GPU 的速度是相当快的,CPU 则在进行数据传输中疲于奔命。因此常常会遇到 GPU 利用率低的问题,这通常是发生在 GPU 等待 CPU 数据传输的情况。所以处理好数据传输,能很好地提高训练速度,最大化硬件资源效率,即最大化硬件资源效率等价于最小化数据传输。
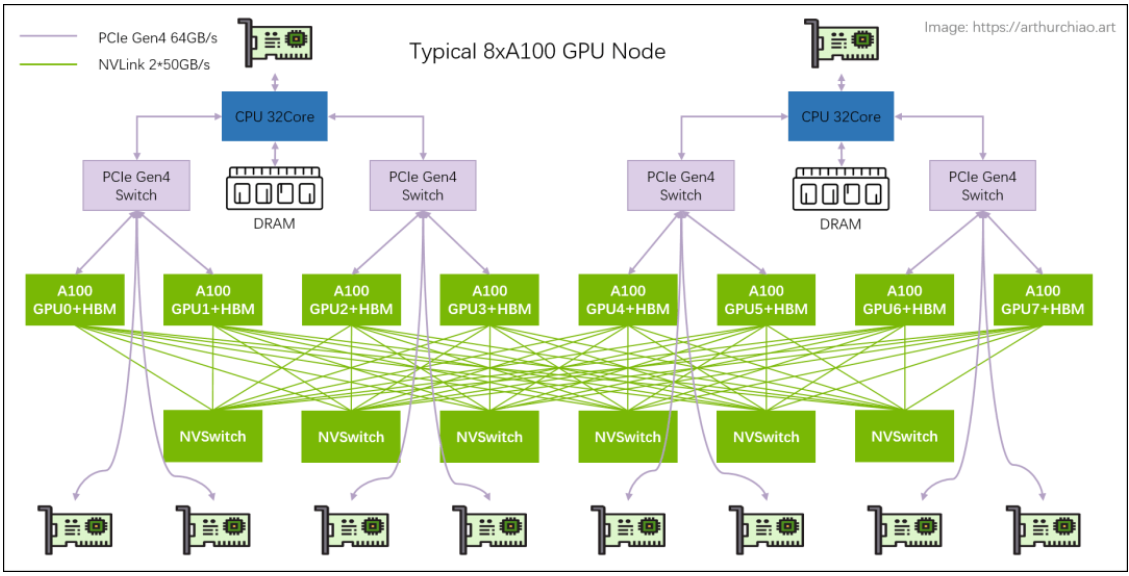
当进行多个 GPU 并行训练时,数据之间的传输更加慢,最大化硬件资源效率等价于最小化数据传输依然正确。
这时候有若干并行性方法去应对这个问题,比如 data parallelism,tensor parallelism 等。
# 6. 推理
# 推理成本 > 训练成本:
随着时间的推移,推理上的成本要超过训练上的成本,这是因为训练的成本通常是一次性的,而推理是按次数而言的,随着用户量增大,使用率提高,推理次数将指数级上升。
# 推理的两个阶段:
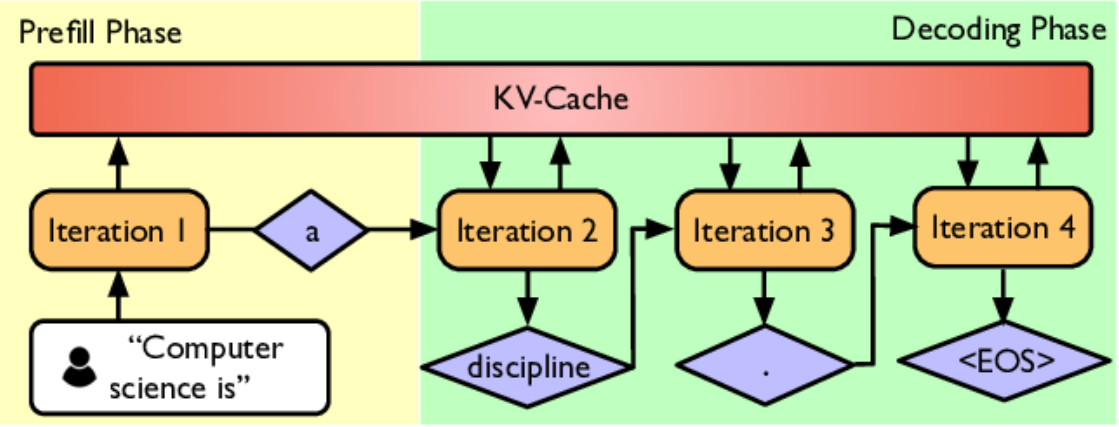
分为 ** 预填充(Prefill)和解码(Decode)** 阶段。预填充一次性将用户提供的 prompt tokens 等上下文处理完毕,包括计算每个位置的隐藏状态以及最后一个位置的 logits 然后存储 KV-Cache,而解码则是在生成过程中逐步追加新 token,每生成一个 token,上下文就变长一点,模型需要用 “旧的 KV 缓存 + 新 token” 再算一次下一个 token 的分布,这个过程将会重复直到生成结束。
因此时间上来讲,预填充是很快的,耗时主要集中于解码。因此有一些手段来加速解码,比如使用小一些的模型进行推理(模型蒸馏、模型剪枝、模型量化),或者是一些特别的策略(先用小而快的模型连续生成一段候选 token,然后由大的模型一次性验证这段候选合理性以决定是否采纳),又或者是在系统方面进行优化(优化 KV-Cache 等)。
# 7.Scaling laws
有时候为大模型做实验时,会遇到这样的问题:在算力预算 C 是固定的情况下,模型参数 N 应该选多大,数据 tokens 数 D 应该为多少,才能最小化自己模型的困惑度?
我们通常会觉得,如果模型越大,其能表达更复杂的规律,但如果给它喂的数据太少就 “吃不饱”。数据量越大,越能让模型充分地学习,但对于小模型会 “吃不下”。所以存在一个 “compute-optimal” 的平衡点。
假设训练一个 Transformer 的 FLOPs 量大致可以写成:C≈kND
- C:总训练 FLOPs
- N:参数量
- D:训练 tokens 数
- k:与架构细节有关的常数
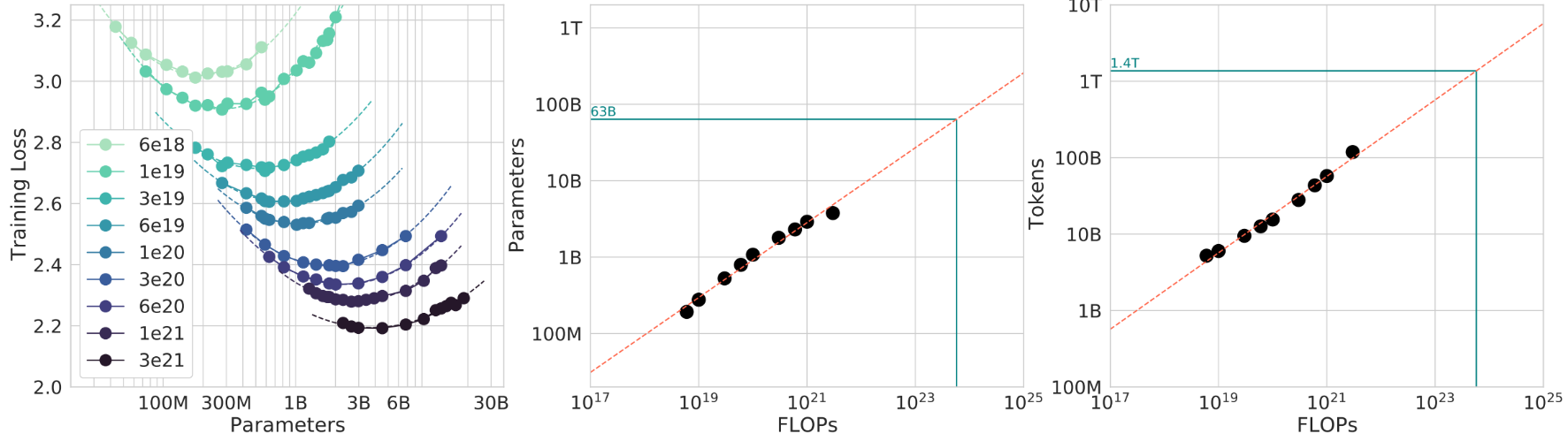
左图的每一条曲线都存在一个临界值,在临界值左边,模型太小,表达能力不够,损失较高。右边则是模型太大,训练效率不足导致的损失上升。将上面公式变形后有:D / N ≈ C / (kN²)。这个公式代表着单个参数所需训练的 tokens 数,即在固定 FLOPs 下随着模型参数 N 变大,每个参数见到的 tokens 变少,因此训练效率变低。
中间的图表示给定一个算力值 FLOPs,模型大概需要多少参数。而右边的图则表示给定一个算力值 FLOPs,模型大概需要多少 tokens 来训练。
Scaling Laws for Neural Language Models 和 Training Compute-Optimal Large Language Models 这两篇文章揭示了这样一个结论:如果你想让模型在当前算力下达到最优,那 N 和 D 大概满足 D ≈ 20 N。这是一种 scaling law。
然而,具体的模型和实验,有自己的 scaling laws。上面两篇论文的工作旨在启发我们要在小规模实验中寻找自己模型的 scaling laws,得到相关规律后预测在大规模实验和应用情境下的表现。
# 8. 对齐
# 对齐方式:
简单讲一下 Alignment。大模型可以分成两种,一种是基础大模型,另一种是指令微调大模型。一般来说,搜集大量数据,用大量显卡训练许久的基础大模型,它能够很好地完成预测下一个 token 的任务,但有时候他所生成的内容并非我们用户想要得到的。
比如,GPT-4 从大量的网络数据中训练得来,未经对齐你就向其发送这样的字符串:“法国的首都是?” 那么其实很有可能 GPT-4 会回复:“法国首都的经纬度是?” 类似这样与回答无关的内容。这是因为它可能是从一个有关法国首都的问题清单中训练的,当你询问其中一个问题时,大模型会返回这个问题后面最后可能出现的内容。
这并非用户想要得到的回答。因此就有了指令微调大模型。基础大模型拥有了强大的预测 tokens 的能力,便可以用指令 - 回答对进行微调,以能够得到强大的问答能力。这是一种对齐方式。
另外还有其他的对齐方式,比如:微调大模型的回答风格(回答格式、回答长度以及回答语气等),还有一些安全性的因素(监督大模型生成的有害、错误的回答)。
相关的对齐方法有监督微调(supervised_finetuning),从反馈中学习(learning_from_feedback)。
# 监督微调:
又称 SFT。给大模型微调的数据格式通常是一问一答:

数据除了一部分是合成数据,大多是人工标注的数据,获取成本和难度较高。
因为基础大模型已经具备了强大的 tokens 预测能力,因此用 SFT 进行微调的时候不必需要大量的数据,LIMA: Less Is More for Alignment 这篇文章表明大概只需要 1000 对数据即可,SFT 主要做的只是让大模型能够从预测 tokens 转向回答和完成用户的问题和要求。
# 从反馈中学习:
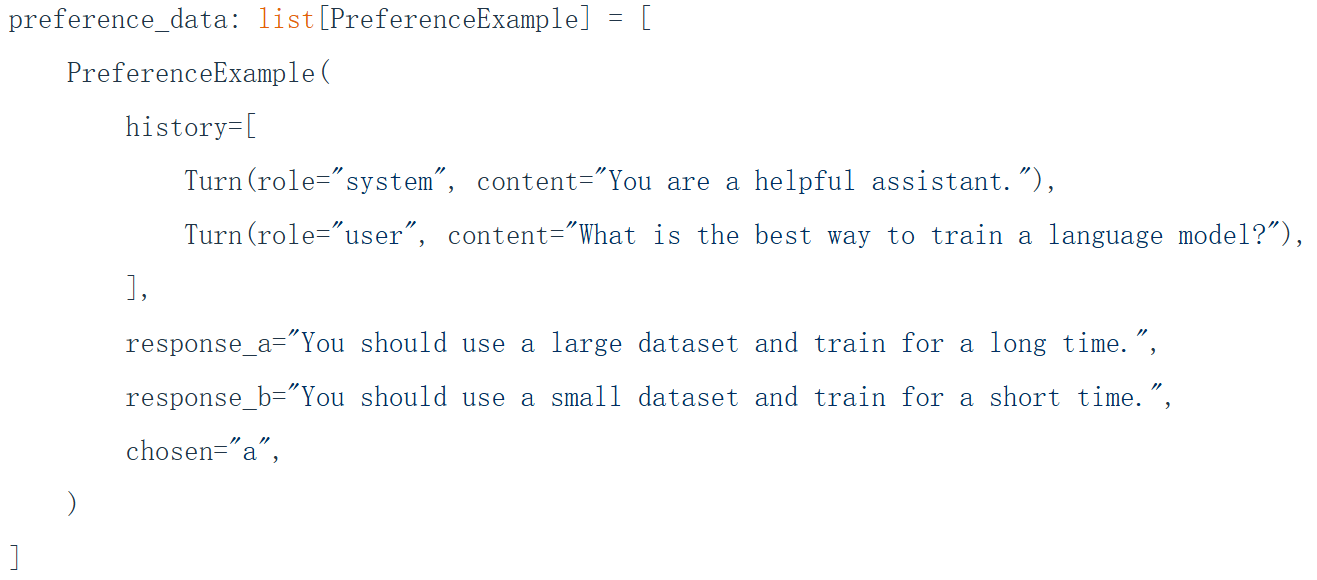
从反馈中学习指的是,给大模型一些基本的例子,在这些例子中问题的回答有两种风格,由人选择其中一个偏爱的回答来微调模型的输出偏好。
可以用一些形式验证器(适用于代码或者数学的输出)或者训练过的验证器(训练一个 LLM 对抗器)对结果是否符合偏好进行验证。
# 9.Tokenization 详解
给一个字符串 "I love LLM",对每一个 Unicode 字符,UTF-8 编码可以将其转换为 8 位二进制序列,得到:
01001001 00100000 01101100 01101111 01110110 01100101 00100000 01001100 01001100 01001101
这样的 indices 序列长度是 80,即 tokens 长度是 80。因为是 8 位二进制序列,因此这样的序列字节数是 10,压缩比是 1 / 8。也就是说每一个 token 只能代表 1 / 8 个字节。这样的序列太长了,太长的序列,LLM 处理所需的时间就更久,我们当然希望一个 token 能代表尽可能多的字节信息,使得序列长度尽可能低。
# Byte Tokenization:
在上面的例子中,用来表示字符的 token 只有 0 和 1 两种。将 token 的种类汇总为字典,字典的大小为 2。因此这种基于二进制位的 tokenization 方式,特点是序列长,字典小。效率更高的方式应该让序列更短,因此通常用字典大小换序列长。
将 8 位二进制转换为整数,得到:
73 32 108 111 118 101 32 76 76 77
一个整数代表一个字节的信息,一个 token 就是一个字节。整数的范围是 0-255。因此字典大小为 256。indices 的长度是 token 的长度,因为像 73 这样的数字在字典中算一个 token,所以 indices 长度是 10。可以计算一下压缩比为 1。这样的序列其实还是太长,效率还不够。
# Character Tokenization:
那么可以考虑将 Unicode 字符表当成 token 字典,一个字符就是一个 token。ASCll 字符是单字节字符,也就是一个字节一个字符,因此全为 ASCll 字符的字符串,压缩比为 1。对于非 ASCll 字符,比如 emoji 和中文或者其他语言,通常是多个字节一个字符,因此这时一个 token 能表示多个字节的信息,此时压缩比通常大于 1。Unicode 字符大约有 15 万个(150K),因此 token 字典大概也有 15 万个。让我们来计算一下这里的压缩比。压缩比是一个 token 能表达的字节信息量。因此压缩比也是 1。
然而,CharacterTokenization 的问题是词表(token 表)太大,实际高频使用的只有一小部分,如此巨大的词表使得 embedding 矩阵相当大,占显存,拖训练和推理速度。对于一些冷门的字符,其与其他高频的字符占用相同的空间大小。更何况,压缩比也不算十分高。
# Word Tokenization:
这个 tokenization 的想法是把一整段字符串按词分开,一个词或者一个标点当作一个 token,然后给这些不同的词分配整数 id,当作词表的一个条目。
通常这种简单的切分方法可以用 regex.findall (r"\w+|.", string) 实现,string 是需要切分的字符串,\w + 分出一个词,点号分出一个标点。比如 “I love LLM” 会被分成 “I”、“love”、“LLM”。
GPT-2 的做法是把单词前面的空格也算在切分的单词里,比如 “I love LLM” 会被分成 “I”、“ love”、“ LLM”。这样能更好处理数字、标点和空白等情况。
切分完毕后,收集训练语料的所有非重复 segement,然后为它们分别分配一个整数 id。
计算一下压缩比。可以知道这时 token 只有 3 个,压缩比为 10 / 3 ≈ 3.33。压缩比较前面的大大提高了。
然而,问题也很明显。由于自然语言中单词非常多,因此词表也还是很巨大。训练时,语料都能在词表字典中找到以映射为整数喂给大模型。但是如果在测试遇到了词表字典中没见过的新词(新造词或者错别字),就会发生未登录词(OOV)问题,只能将这些词映射为统一的 UNK,这会增加困惑度。
# Byte-Pair Encoding(BPE) Tokenization:
BPE 在 Byte Tokenization 基础上做了进一步优化,它在 indices 进行合并同类项的操作,把高频的词或词片段作为一个 token。
以 “the cat in the hat” 为例,首先将字符串按 Byte Tokenization 的方式编码为字节,得到整数序列:116 104 101 32 99 97 116 32 105 110 32 116 104 101 32 104 97 116。这是保证不会发生 OOV 的基础,这是因为无论什么字符(包括中文、emoji),都能拆成 byte,被覆盖到。
词典范围依然是 0-255,长度为 256。
统计相邻 token 对的频率,然后选出频率最高的一对。比如(116,104)出现了 2 次,(104,101)出现了 2 次,(32,99)出现了 1 次,选择频率最高的(104,101),虽然(116,104)也是最高的,但并没有什么影响。说明 104 和 101 可能是某个有意义的子单元,于是将它们进行同类项合并。
为这个频率最高的 Pair 分配一个新整数 id,然后在 indices 中将这个 Pair 替换为这个新整数。比如将(104,101)分配为 256,这个数字正好是词典当前长度。然后在 indices 中将所有(104,101)替换为 256。
重复执行以上操作多次,就能优化序列长度。比如执行 3 次,得到 258 99 97 116 32 105 110 32 258 104 97 116,具体是将(116,104)合并为 256,将(256,101)合并为 257,(257,32)合并为 258。
上面的例子,最终的 indice 长度为 12,原先为 18。计算一下压缩比,压缩比为 18 / 12 ≈ 1.5。
看起来不是很高?上面的合并还不算是最优的结果,毕竟只执行了 3 次循环。你需要训练一个 BPE,使得压缩比尽可能高。
GPT-4,LLaMA 等主流模型都在用 BPE 或其变体,BPE 确实在词表大小、序列长度、鲁棒性之间做了很好的均衡。
