[TOC]
# mv:移动文件
基本格式是:
mv 路径1 路径2 |
如:mv fly doc/fly4。将 fly 文件移动到本级目录的 doc 目录中,更名为 fly4。
mv session session01 |
这个命令将 session 文件更名为 session01。
mv -i session session01
如果目标文件已经存在,-i 同样询问是否要覆盖该文件。
mv note_net* learn/net/note | |
mv note_db* learn/db/note | |
mv note_os* learn/os/note |
星号 * 表示所有,也就是 note_net * 表示所有文件名前面为 note_net 的文件。
mv learn course |
移动目录与移动文件没有区别。这个命令将 learn 目录重命名为 course。
移动某个文件夹中所有内容到另一个文件夹内:
mv /path/to/source/folder/* /path/to/destination/folder/ |
但是,如果源文件夹的文件量过大,就会报这样的错误:
bash: /usr/bin/mv: 参数列表过长 |
当使用通配符 * 扩展的文件数量超过了系统允许的最大命令行参数限制时就会报这个错误。这是 Linux 系统的一个保护机制,防止用户意外执行可能破坏系统的命令。
用这个命令替代以解决:
find /path/to/source/folder/* -mindepth 1 -maxdepth 1 -print0 | xargs -0 mv -t /path/to/destination/folder/ |
# su - 、sudo 与 exit
su - 切换为管理员模式,即 root。
sudo 以管理员的方式运行指令。
exit 退出管理员模式。
# Ed
ed 编辑器命令参数:
a - 在文件的末尾添加新内容 | |
i - 在文件的最后一行之前插入新内容 | |
c - 把文件输入的最后一行替换成新的内容 | |
. - 退出编辑模式,进入命令行模式 | |
w [文件名] - 保存文件 | |
q - 退出ed编辑器 | |
p - 打印某行 | |
$ - 表示最后一行 | |
, - 表示所有行 | |
n - 打印某行 | |
// - 搜索 |
在最后第 3 行替换成新的内容,可以把 - c 改成 - 3c。
关于 p 的用法,也可以用 1p,表示打印第一行,$p 表示打印最后一行。除此之外:
1,$p |
表示从第一行打印到最后一行。类似的用法有:
$-2, $p |
表示从倒数第三行打印到最后一行。
同样可以使用逗号:
,p |
表示打印所有行。
打印还有一种方法:
5n |
用法和效果同 5p,打印第五行。同样可以用
,n 和 1, 3n |
分别表示打印所有行;打印 1 到 3 行。
搜索方法,在两个斜杠之间加入需要搜索的内容即可。
/great/ |
表示搜索含 great 的第一行,然后直接输入:
// |
可以继续搜索含 /great/ 的行。
如果在 ed 编辑器内临时需要使用 shell 命令,可以在命令前加!以表示自己将使用命令而非编辑内容和 ed 内部命令。如:
!wc 文件名 |
将会以!结尾的方式返回需要的内容。
# bc
+ 加法
- 减法
* 乘法
/ 除法
^ 指数
% 余数
quit 退出
# cal
用法:
cal [选项] [[[日] 月] 年]
选项:
-1, --one 只显示当前月份 (默认)
-3, --three 显示上个月、当月和下个月
- s, --sunday 周日作为一周第一天
- m, --monday 周一作为一周第一天
- j, --julian 输出儒略日(显示每一天是本年的第几天)
-y, --year 输出整年
- V, --version 显示版本信息并退出
- h, --help 显示此帮助并退出
# date
date 命令用于 显示 或 设置系统的时间或日期。
格式:date [参数] [+[日期格式]]
常用日期格式:
| 日期格式 | 解释 |
|---|---|
| %t | 输出制表符,tab 键 |
| %H | 小时(00~23) |
| %I | 小时(00~12) |
| %M | 分钟(00~59) |
| %S | 秒(00~59) |
| %j | 今年中的第几天 |
| %Y | 输出年份 |
| %m | 输出月份 |
| %d | 输出日期 |
# fdisk
fdisk 命令可以查看磁盘分区情况和为磁盘进行分区。分区类似于让一个大房子用墙壁按照功能划分为卧室、厕所、厨房、阳台等。
该命令支持的选项有:
选项 说明
- b <size> 扇区大小 (512、1024、2048 或 4096)
-c 兼容模式:“dos” 或 “nondos”(默认)
-h 打印此帮助文本
- u <size> 显示单位:“cylinders”(柱面) 或 “sectors”(扇区,默认)
-v 打印版本信息
- C <number> 指定柱面数
- H <number> 指定磁头数
- S <number> 指定每个磁道的扇区数
fdisk -l 查看所有分区情况
# help、man
1、help
help 命令不带任何参数的话只用于显示内建命令的帮助信息,需要进入到 bash 中使用(上面有讲过内建命令都在 bash 源码中)
注意:因此 help 只能显示内建命令的相关帮助信息显示查询命令的简要说明以及一些参数的使用以及说明,
如果加上 --help 的参数就可以查看外部命令的帮助信息了
2、man
很常见的一个帮助命令,比 help 更加详细,而且无内建命令和外部命令之分,man 好比一个电子词典,里面多是对命令的详细解释信息,help 适合在紧急是忘记用哪个参数的时候用,不太紧急的适合可以用 man。
man 之前说像一本电子词典,那么就应该有相应的章节如下所见:
章节数 说明
1 Standard commands (标准命令)
2 System calls (系统调用)
3 Library functions (库函数)
4 Special devices (设备说明)
5 File formats (文件格式)
6 Games and toys (游戏和娱乐)
7 Miscellaneous (杂项)
8 Administrative Commands (管理员命令)
9 其他(Linux 特定的), 用来存放内核例行程序的文档。
# touch:触碰文件
1.touch 一个不存在的文件可以创建该文件。
2.touch 一个已经存在的文件可以改变该文件的修改时间。
3.touch -d 可以以指定的方式修改文件的修改时间。
4.touch -t 可以以时间戳的格式修改文件的修改时间。
5.touch -a 则表示只修改文件的访问时间。
6. 利用 touch 大量创建文件:如 touch note_{net, db, os}_week {01..16}。该命令会对 net,db,os,01..16 进行排列组合,共 48 个文件会被创建。文件名类似于:note_db_week01,note_db_week02,等等。
# stat:查看状态
stat xxx |
查看该文件的状态 ### stat:查看状态
stat xxx |
查看该文件的状态
# dd:对文件进行数据传输
格式为:dd if=/dev/zero of = 文件名 bs = 大小 count = 个数
/dev/zero 会不断产生 0 数据,然后按照给定的大小,创建若干个相同名字的文件。
除此之外还有其他一些操作:
dd if=/dev/sda of=mbr.bak bs=512 count=1 |
该命令将 sda 设备的第一个分区,也就是引导分区,拷贝 512 个字节到 mbr.bak 文件中。
这个操作需要有管理员权限。
另外需要注意的是,如果不指定 bs 大小,必须要确保 of 文件所在分区大小能够大于 if 文件的大小。
dd if=/dev/urandom of=/dev/sda |
/dev/urandom 将随机把数字覆盖 /dev/sda 中,这个操作就是格式化目标文件。
# mkdir:创建目录
mkdir 路径1 路径2 路径3 路径... |
将创建若干个目录。
mkdir -p learn/{net, db, os}/note |
将依次按照路径创建目录,首先创建 learn,然后创建 net,最后创建 note。
# cp:拷贝
cp fly fly2 |
如果 fly2 不存在,将会创建一个 fly2 文件,然后将 fly 文件拷贝到 fly2 中。
cp -i fly fly2 |
如果 fly2 存在,这个命令系统会询问拷贝时是否要覆盖 fly2 的内容。
cp -p fly fly3 |
这个命令将 fly 文件的内容连同属性也拷贝到 fly3 中。
cp fly tea doc |
当文件名超过 3 个,则会将前面所有的文件或目录拷贝到最后一个目录中。
cp doc/* bak |
这个命令将 doc 目录的所有文件拷贝到 bak 中。
cp -p /usr/share/doc/pam-1.1.8/ doc |
-p 把所有文件内容连同属性拷贝到目标目录中。
cp -f ~/doc /tmp/doc |
-f 强制将~/doc 拷贝到 /tmp/doc 中,如果 /tmp/doc 无法打开,则删除并重试。
# rm:删除文件
基本格式是:
$ rm 路径 |
他会删除路径对应的文件。
$ rm -i doc/fly{2, 4} |
-i 将会询问是否要删除 fly2 和 fly4 两个文件。
$ rm -f doc/fly4 |
-f 将会强制删除文件。
# 杀死进程
首先列出所有进程:
ps aux |
或者搜索你想要杀死的进程:
ps aux | grep [名字] |
找到进程的进程号 PID,使用 kill 命令:
kill -9 PID |
-9 是因为有时候会杀不死进程,这里 - 9 作用是强制杀死
还可以杀死多个进程:
kill -9 PID1 PID2 PID3 ... |
# rmdir:删除空目录
现在有三个空目录:
a1/b1/c1 a2/b2/c2 a3/b3/c3 |
rmdir 将删除路径指定的空目录,基本格式:
$ rmdir 路径 |
如下面的操作将删除 a1/b1 的空目录 c1:
$ rmdir a1/b1/c1 |
如果路径对应的目录不为空,则报错。
$ rmdir -p a2/b2/c2 |
如果路径对应的每一层都是空目录,即 a2 只有 b2,b2 只有 c2,而 c2 没有文件和目录,则可以用 - p 删除所有的空目录,即删除 a2,b2,c2。
如果要删除含文件的目录,还是要使用 rm 命令:
$ rm -r a3 |
将会删除 a3 目录。
$ rm -rf a3 |
-rf 表示强制删除。
# ls:查看文件
$ ls -l 路径 |
-l 可以查看详细信息。在显示的内容中会有类似 lrwxrwxrwx 的内容,第一个字母是文件的类型。
-,减号表示这是一个普通文件。l 表示这是一个符号链接。
b 表示这是一个块特殊文件,比如磁盘分区。
c 表示这是一个字符特殊文件,比如这是一个终端。
d 表示这是一个目录。
p 表示这是一个命名管道(FIFO)。
s 表示这是一个套接字。
?表示这是一个其他类型文件。
$ ls -i 文件 |
-i 可以查看文件的 Inode,关于 Inode 可以看文件的 Inode 部分。
$ ls -R a |
递归查看 a 目录下的所有文件、目录,目录的子目录等。
# ln:创建链接
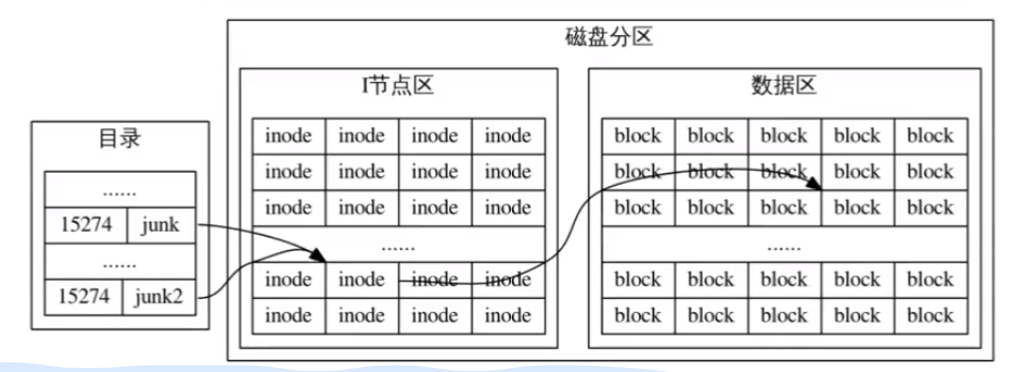
Linux 的目录实际上是一个文件名列表,内容是文件名 + Inode 号。Inode 号实际上就是一个引用,而文件名 + 引用就是一个链接。当打开某个文件 junk 时,会通过这个文件的 Inode 号,在当前磁盘里的 I 节点区寻找对应的 I 节点,然后根据 I 节点,再找到对应的数据。
一个文件可以有多个链接,比如上图的 junk 和 junk2 的 Inode 号都相同,也就是都指向磁盘中的同一块数据区,因此这个文件有两个链接 junk 和 junk2。
链接分为硬链接和符号链接。
硬链接的 Inode 号是一样的,指向磁盘中同一个 I 节点区,而且它们的 Inode 属性都是一样的,也就是文件大小一样,修改时间一样。
符号链接则是在原有硬链接的基础上新增一个链接,这个链接的 Inode 号与硬链接不一样。它在磁盘的 I 节点区新增一个 Inode,这个 Inode 指向与硬链接相同的数据区。
符号链接往往比硬链接的大小要小得多,类似于 Windows 的快捷方式。同一个文件可以创建多个不同的符号链接,这些符号链接的 Inode 并不一致,但都指向该磁盘分区的同一块数据区。
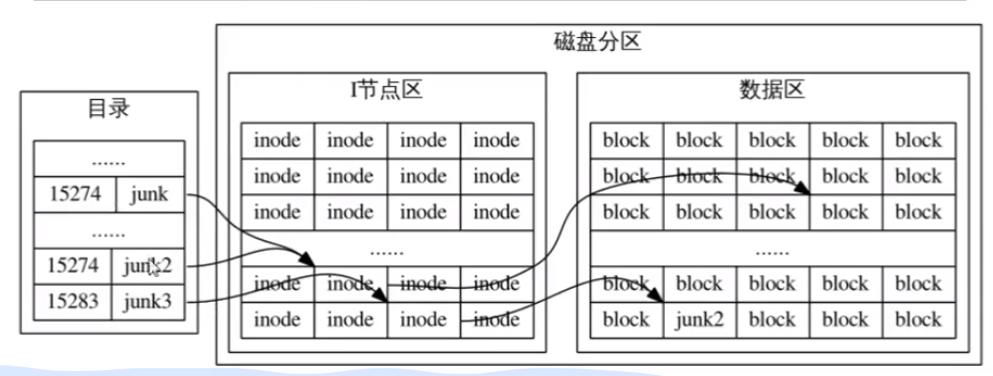
$ ln junk junk2 |
这个命令,将为 junk 文件创建一个硬链接,于是这个文件有两个硬链接,一个是 junk 一个是 junk2。
创建硬链接有两个限制,第一个限制是不允许跨磁盘分区创建硬链接,第二个限制是不允许为目录创建硬链接。
第一个限制的原因是,在当前磁盘分区内,目录的所有文件的 Inode 彼此是不同的,然而不同磁盘分区的文件,Inode 却是可能相同的,比如 A 分区某目录有 junk 文件,Inode 号为 15274,很容易在 B 分区某目录中找到一个文件的 Inode 号与 junk 一样。因此,创建硬链接时,会导致错误:
$ ln /A/a/junk /B/b/junk2 |
这个命令是错误的,它企图在 B 分区的 b 目录下,创建 A 分区 a 目录下 junk 文件的硬链接。
第二个限制的原因是,Linux 系统会通过点号(. 或..)文件自主维护目录的硬链接,因此不允许为目录创建硬链接。
通过下面的命令可以创建符号链接:
$ ln -s junk2 junk3 |
这个命令,将为 junk2 文件(硬链接)创建一个符号链接 junk3。
符号链接依赖其目标文件,当目标文件的硬链接都不再存在,符号链接会失效,当恢复目标文件的硬链接,符号链接就会恢复。
# file:查看文件类型
$ file /usr/bin/cat | |
directory |
显示文件类型,如 l,d,-,p 等。
# od:按字节查看文件内容
$ od -bc .bashrc |
od 命令以八进制或十六进制显示文件的内容。
-bc 选项中的 c 是每个字节打印一个字符,b 是每个字节打印其对应的八进制。
$ od -A x -t x1z -v .bashrc |
这个命令,-A x 表示地址以十六进制的形式显示。-t 是内容显示的格式,-t x1z 的 x 表示内容以十六进制的形式显示,1 是一个字节,z 是显示字符。-v 是如果显示的内容某些行完全一样,则完全显示出来而不是使用星号省略。
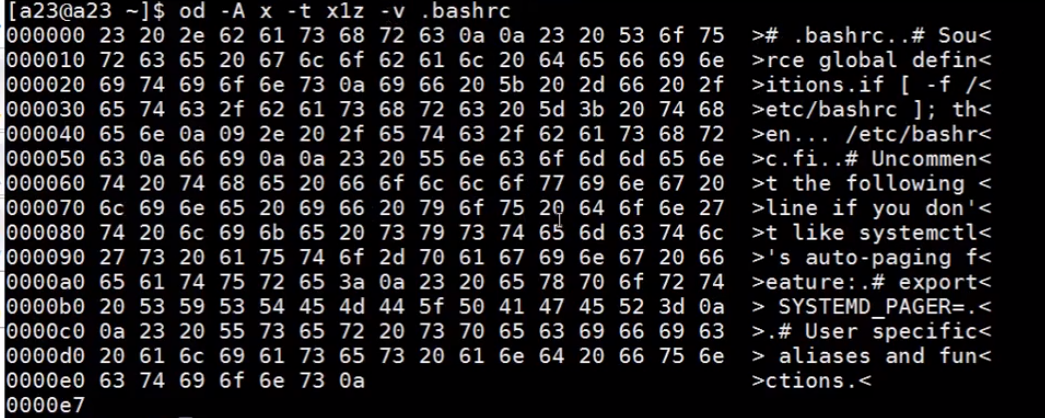
$ od -A x -t x1z -j 16 -N 16 -v .bashrc |
这个命令的 - j 表示地址跳到第 16 个字节位置开始显示。-N 表示只显示 16 个字节(一行)的内容。
有一个类似的命令叫做:hexdump
# hexdump:按字节查看文件内容
$ hexdump -bc .bashrc |
与 od 不同,hexdump 的地址是默认以十六进制的形式显现。-bc 作用与 od 一样,显示一个字节内容对应的八进制和字符。
$ hexdump -C .bashrc |
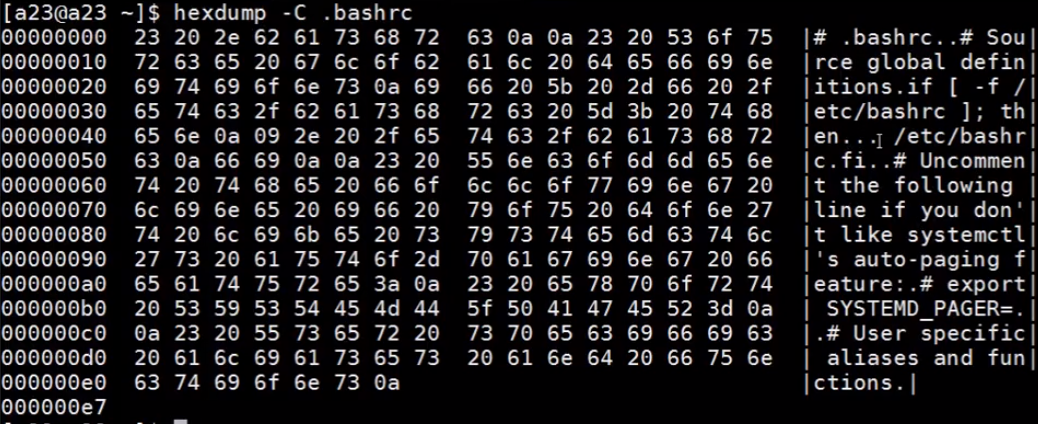
hexdump 如果不加 - bc 选项,则显示内容时默认以十六进制显示,-C 就是将每个十六进制内容以字符的方式显示在右边,无法打印的字符用点号显示。
$ hexdump -s 16 -n 32 -C .bashrc |
hexdump 的 - s 选项和 od 的 - j 选项作用一样,就是跳过 16 个字节(一行)打印。-n 作用与 od 的 - N 一样,就是限定显示字节的个数,32 表示只显示 32 个字节,也就是两行。
# wc:显示文件的行数,单词数,字符数。
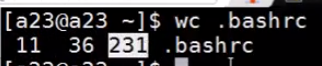
$ wc .bashrc |
这个命令将会依次以:行数 单词数 字符数 文件名,显示出来。
# mail:给不同用户发送邮件
$ mail 用户名 文件 |
如:
$ mail tom letter |
这时候在 tom 用户内输入 mail,然后选择邮件号,即可查看收到的邮件。
# 文件的 Inode
每个文件都有一个 Inode,Inode 包含了文件的管理信息,比如修改时间,权限,文件大小,文件位置等。每个文件的 Inode 号唯一,可以表示文件在磁盘中的位置。
$ ls -i 文件 |
可以查看文件的 Inode 号。
# 文件名通配符
# 星号 *
匹配任意长度的文件名字符串,但不匹配点号 . 开头的文件。如 * file 匹配 file , makefile ,但不匹配 .profile 。除非:
$ .*file |
星号也可以通配目录名。
这会涉及到显示隐藏文件的方法,下面的语句将会显示所有点号开头的隐藏文件:
$ ls .* |
# 问号?
匹配单个任意字符:
$ ls week?_note | |
week8_note |
# 方括号 []
匹配单个括号内的任意字符。
$ ls [Ff]ile[abc].txt | |
Filea.txt Filec.txt fileb.txt |
从 [Ff] 中选择一个字符与后面的 ile 匹配,同样的取 [abc] 中任意一个字符与.txt 匹配。理想排列组合有 2 * 3 == 6 中情况,但需要根据实际看是否确实有这个文件。
$ ls a[0-9].log [a-m]01.log |
方括号内使用 -,可以规定字符范围。
$ ls a[!0-9].log [^a-m]01.doc |
方括号前用!和 ^ 表示否定的意思,也就是不显示含方括号内指定字符的文件。
# 大括号扩展 {}
组合用法:
$ echo {a,b,c}{d,e,f} | |
ad ae af bd be bf cd ce cf |
注意大括号内的逗号后面不能有空格。
表示 a,b,c 与 d,e,f 排列组合,然后执行命令。
$ touch day{1..7}.log |
用两个句点 . 表示范围,将创建 7 个文件。
大括号与方括号不同,大括号更倾向于用在创建文件和目录中。方括号在匹配的时候只能匹配到已有的文件,更倾向于查找。
比如:
$ touch month[1-9].log |
由于并不存在九个这样的文件,因此方括号无法进行匹配,touch 命令就会直接创建名为 month [1-9] 的 log 文件。
大括号里句点的用法还可以是:
$ echo a{000..100..10} | |
a010 a020 a030 a040 a050 a060 a070 a080 a090 a100 |
第一个 .. 表示范围,从 000 到 100。第二个 .. 后面的内容表示步长,表示一次走 10 个数,因此创建了 010,020……100 共十个文件。
一个创建目录的用法:
$ mkdir -p a/{b/{c,d},e/{f,g}} |
# 特殊字符与引用
Linux 存在一些特殊字符。如~,*,?,#,$,\,`,!,<,>,;,() 等。
其中,$ 符号表示将后面变量的值取出来,比如 $HOME。! 表示查找历史命令,!2 表示第二个命令。
引用的意思差不多是转义的意思。有时候我们想直接打印这些特殊字符而不是使用这些特殊字符的实际意义。方法有三种:
- 反斜杠(“\”):可以对后面的单个特殊字符进行引用(转义)。
- 双引号(弱引用):引用除 $ \ ` ! 之外的特殊字符。
- 单引号(强引用):引用所有特殊字符。
# IO 重定向
# 标准文件描述符
每个 shell 命令都从 shell 继承了三个标准文件描述符:
0:标准输入文件(stdin)
1:标准输出文件(stdout)
2:标准错误文件(stderr)
默认情况下,三个标准文件描述符都连接终端。
# 标准输入重定向 <
$ cat | |
Hello Linux! | |
Hello Linux! |
cat 命令不加文件名,默认从终端获取数据,也就是从用户输入到终端的内容获取。
$ cat <fly | |
xxxxxxxx | |
xxxxxxx | |
xxxxxx | |
xxxxx | |
xxxx | |
xxx | |
xx | |
x |
小于号 < 表示输入重定向。这个命令,bash 会打开 fly 文件,然后将 cat 的输入重定向到 fly 文件,cat 命令从 fly 文件读取数据,然后执行 cat 命令。
这个过程可以从 wc 命令中理解:
$ wc <students.db | |
10 50 190 | |
$ wc students.db | |
10 50 190 students.db |
第一个命令,bash 首先打开 students.db,然后将 wc 命令的 stdin 重定向到 students.db,wc 只获取了 students.db 的数据,并不知道有 students.db 这个文件。
第二个命令,由 wc 命令亲自打开 students.db 文件,然后执行 wc 命令,所以后面会有文件名。
# 标准输出重定向 >
$ ls >ls.out | |
$ cat ls.out | |
file1.txt file2.txt file3.txt |
大于号 > 将 shell 命令的输出重定向到指定文件。
假如用户打开了两个本地虚拟终端,pts/0,pts/1。我们可以在 pts/0 终端输入:
$ echo hello world >/dev/pts/1 |
这意味着将 echo 命令的输出重定向到 /dev/pts/1 终端屏幕,然后执行 echo hello world,输出在 /dev/pts/1 终端屏幕中出现。
$ cat file1 | |
this is file1 | |
$ cat file2 | |
this is file2 | |
$ cat file{1,2} >allfile | |
$ cat allfile | |
this is file1 | |
this is file2 |
这是一个拷贝的操作。首先 bash 检查输出重定向目标文件是否存在,如果存在,由于是单个输出重定向符号 >,因此将删除目标文件的内容,如果不存在,将创建该文件。然后将 cat 命令输出重定向到 allfile,cat 执行命令,查看 file1 与 file2 两个文件的内容,然后将查看的内容输出到 allfile 而不是终端屏幕中。
这里涉及到覆盖式输出重定向 >,它将删除目标文件的内容。追加式输出重定向 >>,它则在目标文件的末尾追加内容。
# 关于输入重定向和输出重定向的组合用法
$ cat <file1 >file4 | |
$ cat file1 | |
this is file1 | |
$ cat file4 | |
this is file1 |
这有点类似于拷贝。
$ cat >hellolinux | |
linux is a good os. | |
we should learn linux. | |
good luck. | |
$ cat hellolinux | |
linux is a good os. | |
we should learn linux. | |
good luck. |
没有为输入重定向,因此从键盘所输入的内容执行 cat,然后将输出结果重定向到 hellolinux 文件中。
来看下面有意思的例子:
$ wc temp | |
5 23 240 temp | |
$ wc temp >temp | |
0 0 0 temp |
为什么有这样的结果?首先 bash 将 wc 输出重定向为 temp 文件,在此过程中,发现 temp 文件以存在,由于不是追加式输出重定向 >>,因此删除 temp 中的内容,然后执行 wc temp。没有内容,自然是 0 0 0 temp。
# 标准错误重定向 2>
假如 .profile 是一个不存在的文件:
$ ls .bashrc .profile >ls.out | |
ls: cannnot access .profile: No such file or directory | |
$ cat ls.out | |
.bashrc |
命令企图将两个文件的信息输出重定向到 ls.out 文件,然而 .profile 文件不存在,因此将报错内容输出到终端屏幕,而存在的文件 .bashrc 的信息被正常输出到 ls.out 。
可以指定报错输出的位置,也就是进行 shell 命令的错误重定向。
# 过滤器
过滤器在 Linux 的作用是从标准输入读取输入数据,对其进行简单的变换,然后将其结果写入标准输出。这个过程并不改变原始文件。
# grep
$ grep 'as far as' theRoad | |
Because it was grassy and wanted wear; | |
Somewhere ages and ages hence: | |
Two roads diverged in a wood, and I- |
grep 对文本进行过滤,theRoad 是目标文件,‘as far as’是过滤依据的文本。这个命令的作用是在 theRoad 中找到含‘as far as’的行,从原文件中过滤出来并显示到标准输出 —— 终端界面上。
当 grep 含多个参数时,将第一个参数以外的参数作为过滤对象。
$ grep -i 'and' theRoad |
-i 选项是忽略大小写。
$ grep -n 'wood' theRoad | |
3:Two roads diverged in a yellow wood, | |
20:Two roads diverged in a wood,and I- |
-n 选项是在显示含‘wood’行时,同时显示其行号。
$ grep -vn 'the' theRoad | |
#文本略 |
-v 选项是寻找除‘the’之外行,从目标文件 theRoad 中过滤出来,然后显示到标准输出上。这个比较常用。
$ grep -ic 'road' theRoad | |
# 文本略 |
-c 选项是计数含‘road’行的个数。
# cut
cut 命令将过滤列的内容,也就是会对每行进行过滤。
假设有 students.db 文件,文本内容为:
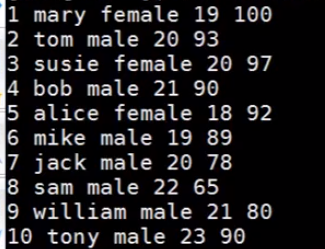
$ cut -c3 students.db |
-c 选项是指定搜索某列的字符,并显示到标准输出中。该命令将搜索 students.db 文件每行第三列的字符,并从文件中过滤出来。

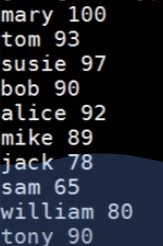
$ cut -d' ' -f2,5 students.db |
-f 选项将过滤每一行某列的字段,-d 选项是指定文本分割符。
上述命令的效果是从 students.db 文件中过滤每一行第二个字段和每一行第五个字段,以一个空格作为分隔符。效果:
$ cut -d' ' -f2-5 students.db |
这个命令则是过滤每一行第二个字段到第五个字段。
# tr
tr 命令对目标文本进行简单的变换操作。
$ echo 'what are you doing?' | tr 'a-z' 'A-Z' | |
WHAT ARE YOUR DOING? |
这个命令,将目标文本中的小写字母‘a-z’对应地转换为大写字母‘A-Z’,这要求第一个参数的长度要与第二个参数的长度一致。这两个参数像是词典,tr 将第一个词典映射为第二个词典。
$ echo 'batterfly' | tr 'a-z' 'n-za-m' | |
ohggresyl |
第二个参数表示从 n 到 m,中间的 za 是必填项。a 会转换为 n,z 会转换为 m。同理,两个参数的长度需要一致。
$ cat >file.txt | |
how do you do | |
how are you? | |
$ tr '\t' ' ' <file.txt | |
how do you do | |
how are you? |
这个应用,是将 file.txt 中的 Tab 符转换成空格。
$ echo '1a22bb333ccc' | tr -d '0-9' | |
abbccc |
-d 选项,将指定内容删除。
$ echo '1a22bb333ccc' | tr -c -d '0-9' | |
122333 |
-c 选项是补集的意思,这个命令就是将 0-9 之外的所有内容删除。同理,它自然删除了换行符。
$ echo 'GNU is nooooot Unix' | tr -s 'o' |
-s 选项将目标内容压缩,这个命令将所有连续的 o 压缩为一个 o。因此,也可以对多个空格进行压缩,压缩为以单一空格分隔的文本:
$ cat >file.txt | |
how do you do | |
how are you? | |
$ tr -s ' ' | |
how do you do | |
how are you? |
同样可以对多个空行进行压缩:
$ tr -s '\n' |
# sort
假设有这样一个文件 booklist,记录了书名 ^ 作者 ^ 出版年份 ^ 价格,^ 是字段分隔符:
$ cat booklist | |
All the light we cannot see^Anthony Doerr^2014^$15.29 | |
Saga, Vol.1^Brian K. Vaughan^2012^$8.46 | |
The blood of Olympus^Pick Piordan^2014^$11.99 | |
Winter(Lunar)^Marissa Meyer^2015^$13.84 | |
The day the crayons quit^Drew Daywalt^2013^$10.32 | |
The girl on the train^Paula Hawkins^2015^$14.01 | |
Red queen^Victoria Aveyard^2012^$10.58 |
sort 命令是对文件以字典序的方式进行每行排序,每行从第一个字符开始,按照 a<b<c<……<z 的方式进行排序,第一个字符相同则比较第二个字符,以此类推。这是默认的,从小到大进行排序。
$ sort booklist | |
All the light we cannot see^Anthony Doerr^2014^$15.29 | |
Red queen^Victoria Aveyard^2012^$10.58 | |
Saga, Vol.1^Brian K. Vaughan^2012^$8.46 | |
The blood of Olympus^Pick Piordan^2014^$11.99 | |
The day the crayons quit^Drew Daywalt^2013^$10.32 | |
The girl on the train^Paula Hawkins^2015^$14.01 | |
Winter(Lunar)^Marissa Meyer^2015^$13.84 |
现在我们想要对第三个字段,即出版年份进行排序,可以结合 - k 选项与 - t 选项。
$ sort -t^ -k3 booklist | |
Saga, Vol.1^Brian K. Vaughan^2012^$8.46 | |
The day the crayons quit^Drew Daywalt^2013^$10.32 | |
The blood of Olympus^Pick Piordan^2014^$11.99 | |
All the light we cannot see^Anthony Doerr^2014^$15.29 | |
Red queen^Victoria Aveyard^2012^$10.58 | |
Winter(Lunar)^Marissa Meyer^2015^$13.84 | |
The girl on the train^Paula Hawkins^2015^$14.01 |
-t 选项,指定字段的分隔符,这里将 ^ 作为分隔符。-k 选项指定排序的字段,没有这个选项将对全部字段进行排序。
一般来说,默认排序的数据类型是字符,可以指定排序数据类型是数字,用 - n 选项。比如打算对第四个字段的价格进行排序。然而,第四个字段不纯为数字,还有字符 $,这时候就要用一个小技巧:
$ sort -t^ -k4.2n booklist | |
Saga, Vol.1^Brian K. Vaughan^2012^$8.46 | |
The day the crayons quit^Drew Daywalt^2013^$10.32 | |
Red queen^Victoria Aveyard^2012^$10.58 | |
The blood of Olympus^Pick Piordan^2014^$11.99 | |
Winter(Lunar)^Marissa Meyer^2015^$13.84 | |
The girl on the train^Paula Hawkins^2015^$14.01 | |
All the light we cannot see^Anthony Doerr^2014^$15.29 |
可以看到已经按照价格进行排序。注意到,-k4.2 表示,从第 4 个字段第二个字符开始进行排序。-n 指定了排序的数据类型是数字。
可以用 - r 选项进行从大到小排序:
$ sort -t^ -k4.2nr booklist | |
All the light we cannot see^Anthony Doerr^2014^$15.29 | |
The girl on the train^Paula Hawkins^2015^$14.01 | |
Winter(Lunar)^Marissa Meyer^2015^$13.84 | |
The blood of Olympus^Pick Piordan^2014^$11.99 | |
Red queen^Victoria Aveyard^2012^$10.58 | |
The day the crayons quit^Drew Daywalt^2013^$10.32 | |
Saga, Vol.1^Brian K. Vaughan^2012^$8.46 |
假设有这样一个文件,记录了产品的:型号 销量 价格,这里用空格作为分隔符,所以我们不需要设定 - t 选项参数。
$ cat sale.log | |
HZ55E7D 3789.00 2000 | |
EX65E3A 3299.00 1600 | |
FY75E3D 4499.00 800 | |
NM65E5D 4389.00 1600 | |
HZ55E5D 3299.00 2000 | |
TD55E3A 2099.00 5000 | |
HU65E3D 3789.00 2000 | |
SR75E5D 6689.00 800 |
前面实现了对某个字段进行排序,甚至对某个字段的后面部分进行排序,我们还可以指定字段中间部分进行排序,只需要确定范围即可:
$ sort -k1.3, 1.4n sale.log | |
HZ55E5D 3299.00 2000 | |
HZ55E7D 3789.00 2000 | |
TD55E3A 2099.00 5000 | |
EX65E3A 3299.00 1600 | |
HU65E3D 3789.00 2000 | |
NM65E5D 4389.00 1600 | |
FY75E3D 4499.00 800 | |
SR75E5D 6689.00 800 |
用逗号选取某个字段内的部分进行排序。
假如我们要让第一步排序中,相同的部分进行第二步排序,可以继续在第一个 - k 选项接一个 - k 选项。
$ sort -k1.3, 1.4n -k3nr sale.log | |
TD55E3A 2099.00 5000 | |
HZ55E5D 3299.00 2000 | |
HZ55E7D 3789.00 2000 | |
HU65E3D 3789.00 2000 | |
NM65E5D 4389.00 1600 | |
EX65E3A 3299.00 1600 | |
FY75E3D 4499.00 800 | |
SR75E5D 6689.00 800 |
同理,可以对第二个字段进行第三步排序。
$ sort -k1.3, 1.4n -k3nr -k2nr sale.log | |
TD55E3A 2099.00 5000 | |
HZ55E7D 3789.00 2000 | |
HZ55E5D 3299.00 2000 | |
HU65E3D 3789.00 2000 | |
NM65E5D 4389.00 1600 | |
EX65E3A 3299.00 1600 | |
SR75E5D 6689.00 800 | |
FY75E3D 4499.00 800 |
当第一个字段 —— 型号相同时,比较第三个字段价格,当第三个字段也相同,比较第二个字段价格。-r 选项进行从大到小排序。
可以用输出重定向保存排序结果,但是不要这么做:
$ sort -k1.3, 1.4n -k3nr -k2nr sale.log >sale.log |
这会首先将 sale.log 文件内容清空再排序,排了个寂寞,应该选择其他文件:
$ sort -k1.3, 1.4n -k3nr -k2nr sale.log >sale.sort |
注:Linux 扩展名随便取。
# uniq
不带选项的 uniq 删除相邻重复的行。
$ cat numlist | |
123 | |
123 | |
30 | |
56 | |
123 | |
78 | |
78 | |
$ uniq numlist | |
123 | |
30 | |
56 | |
123 | |
78 |
如何删除所有重复行?可以先 sort,将第一个字段相同的排到一起,然后再 uniq:
$ sort numlist | uniq | |
30 | |
56 | |
78 | |
123 |
-d 选项表示显示文件中重复的行的内容。
-u 选项表示显示文件中非重复行的内容。
其实我说实话 - d 和 - u 选项更好用,尤其是 - u,可以直接代替 sort+uniq 两步操作。
-c 选项显示文件每一行重复的次数。
# join
join 将多个文件按照相同字段连接到一起。假设有 students 文件和 score 文件:
$ cat students | |
tom 202026202031 23 | |
mary 202026202017 21 | |
bob 202026202009 22 | |
susie 202026202026 20 | |
alice 202026202042 19 | |
mike 202026202011 22 | |
$ cat score | |
202026202017 C262243 98 | |
202026202031 C262243 100 | |
202026202042 C262243 96 | |
202026202011 C262243 90 | |
202026202026 C262243 93 | |
202026202009 C262243 88 |
可以这么操作:
$ sort -k2 students >left | |
$ sort -k1 score >right | |
$ join -12 -21 left right | |
202026202009 bob 22 C262243 88 | |
202026202011 mike 22 C262243 90 | |
202026202017 mary 21 C262243 98 | |
202026202026 susie 20 C262243 93 | |
202026202031 tom 23 C262243 100 | |
202026202042 alice 19 C262243 96 |
经过两次 sort,students 与 score 的学号字段都一致。然后进行 join,-12 与 left 文件对应,-21 与 right 文件对应,-12 表示以第一个文件的第二个字段为重复字段,-21 表示以第二个文件的第一个字段为重复字段。
# paste
paste 命令是将多个文件拼接到一起。注意,paste 与 join 不同的地方在于,join 以公共字段进行连接,而 paste 是直接将多个文件的内容拼接到一起。假设有三个文件 s_name,s_gender,s_age,对他们进行拼接:
$ cat s_name | |
tom | |
mary | |
bob | |
susie | |
alice | |
mike | |
$ cat s_gender | |
male | |
female | |
male | |
female | |
female | |
male | |
$ cat s_age | |
23 | |
22 | |
21 | |
20 | |
19 | |
20 | |
$ paste s_name s_age s_gender | |
tom 23 male | |
mary 22 female | |
bob 21 male | |
susie 20 female | |
alice 19 female | |
mike 20 male |
paste 的文件是有顺序的,即 s_name s_age s_gender 与 s_age s_gender s_name 是不同的。
-d 选项是指定拼接结果的分隔符:
$ paste -d'*' s_name s_age s_gender | |
tom*23*male | |
mary*22*female | |
bob*21*male | |
susie*20*female | |
alice*19*female | |
mike*20*male |
-s 选项可以在拼接的结果上进一步进行转置:
$ paste -s s_name s_age s_gender | |
tom mary bob susie alice mike | |
23 22 21 20 19 20 | |
male female male female female male |
# comm
comm 显示多个文件相同的部分和各自独有的部分。假设有两个文件 groupA 与 groupB:
$ cat groupA | |
mary | |
bob | |
tom | |
alice | |
jack | |
$ cat groupB | |
mike | |
alice | |
bob | |
mary | |
andy | |
peter |
comm 使用前,需要文件已经经过一次 sort。
$ sort groupA >listA | |
$ sort groupB >listB | |
$ comm list[AB] | |
alice | |
andy | |
bob | |
jack | |
mary | |
mike |
显示的结果有三列,最后一列是各个文件中公共行。第一列是第一个文件的独有行,第二列是第二个文件的独有行。
当然这么做可以不显示结果的特定列:
$ comm -12 list[AB] | |
alice | |
bob | |
mary |
-12 表示不显示结果的第一列和第二列。
# diff
以前面的 listA 和 listB 为例:
$ cat -n listA | |
1 alice | |
2 bob | |
3 jack | |
4 mary | |
5 tom | |
$ cat -n listB | |
1 alice | |
2 andy | |
3 bob | |
4 mary | |
5 mike | |
6 peter | |
$ diff -u listA listB | |
--- listA 2020-03-02 21:46:15 +0800 | |
+++ listB 2020-03-02 21:46:21 +0800 | |
@@ -1.5 +1.6 @@ | |
alice | |
+andy | |
bob | |
-jack | |
mary | |
-tom | |
+mike | |
+peter |
diff 不带选项显示的结果会十分难读。常用的选项有 - u。
-u 选项以更易读的方式显示两个文件的区别。
--- listA |
三个减号表示第一个文件。
+++ listB |
三个加号表示第二个文件。
-u 以第一个文件为主体,显示第二个文件相较第一个文件的变化。加号表示增加,减号表示删除。
alice 前面没有加减号,表示与第二个文件相同。+andy,表示第二个文件比第一个文件多出一个单词 andy,应该增加 andy。-tom 表示第一个文件应该删掉 tom,也就是第一个文件比第二个文件多出一个单词 tom。
$ diff -u listA listB >A-B.patch |
可以将差异输出重定向到一个文件,这个文件被称为补丁文件,记录了以第一个文件为主体与其他文件的差异。这个补丁文件可以给主体文件打补丁。参见 patch。
当然,有更加规范、固定的方法生成一个补丁文件:
$ diff -Naur tower1 tower2 > tower.patch |
# patch
patch 命令为某个文件打补丁,如下方的命令,将为 listA 打补丁。这个 - p 选项后面会提。
$ patch -p1 listA <A-B.patch | |
patching file listA |
打完补丁的 listA,将与 listB 相同:
$ diff listA listB |
终端没有继续显示内容,表示两个文件相同。
$ patch -Rp1 listA < A-B.patch |
-R 选项将为已打补丁的 listA 重置为原来未打补丁的内容。
前面都是为文件打补丁,现在我们尝试为文件夹、目录打补丁。假设 tower1,tower2 都是目录,各含若干文件。
$ diff -Naur tower1 tower2 > tower.patch | |
$ cd tower1 | |
$ patch -Np1 <../tower.patch |
首先,新生成一个以 tower1 为主体的补丁文件 tower.patch。然后进入 tower1 目录内,使用 patch 命令打补丁。这里,-N 选项是正向打补丁,跟前面的 - R 是反过来的意思,-p1 选项是当在 tower1 内,也就是在主体文件内打补丁时才使用的选项,当执行 cd 进入到 tower1 的子目录内进行打补丁时,就会使用 - p2,以此类推。但是 - p1 较为常用。
# 正则表达式
# 基本正则表达式元字符(BRE)
# . 句点
句点,表示单个任意字符,除了换行符。
$ grep 'a.b' rfile | |
$ grep 'a\.b' rfile |
‘a.b’表示的意思是,含 a.b 的任意字符串,a 与 b 中间是任意单个字符。
如果想要把这个元字符当普通的句点。处理,可以在前面加反斜杠 \。
# […] 中括号
中括号可以表示这个括号中任意一个字符。
$ grep '[0-9]\.[0-9]' rfile |
[0-9] 表示 0 到 9 之间任意一个数字,\. 表示普通句点,所以这个正则表达式是各种诸如‘a8.0dadw’,‘wdwaw2.3de’,‘dd2.9wvff9.5pppk7.6dw’…… 之类的字符串,两个数字之间含一个句点。
中括号里最前面若有尖号 ^ 则表示否定:
$ grep '[^0-9][0-9][^0-9]' rfile |
[^0-9] 表示单个非数字字符。这个正则表达式是诸如:‘w9w’,‘dw9wd0vvxx’…… 的字符串。
# 星号
星号表示某个字符出现 0 次或 0 次以上。
$ grep '[0-9][0-9]*' rfile |
表示一个数字可以不出现或者出现若干次,诸如:‘dwd79fwwd’,‘uf79999w’,‘wd7wdda’的字符串。
# ^x 尖号
尖号表示行首:
$ grep '^#' .bash_profile | |
$ grep -v '^#' .bash_profile | |
$ grep '^[^#]' .bash_profile |
‘^#’表示行首是 #的字符串,诸如:‘# if (data == 1):’,‘# while (flag == 1):’等。
# x$ 美元符
美元符表示行尾:
$ grep '[!?.]$' rfile | |
$ grep '\...$' rfile | |
$ grep -v '^$' .bash_profile |
‘[!?.]$’的意思是 rfile 中每个以?或!或。结尾的行。
注意:当‘.’,‘*’和‘$’出现在 […] 中时,以及‘^’没有放在 […] 里面的最前面时,都被当作普通字符处理。
# 扩展正则表达式元字符 (ERE)
# grep -E 与 egrep
grep -E 选项与 egrep 的作用完全相同,都是将后面的字符串当作扩展正则表达式的字符串。(基本表达式元字符的功能还在)
如果想要使用扩展正则表达式元字符,需要在这些元字符前加一个反斜杠。
# x+ 加号
加号表示左边的字符出现 1 次以上。
$ grep '^[0-9]+$' rfile | |
$ grep '^[0-9]\+$' rfile |
第一个命令的正则表达式并不是扩展正则表达式元字符,它企图使用 + 加号元字符,然而并没有使用反斜杠,因此这个正则表达式是基本正则表达式。
第二个命令的正则表达式是扩展正则表达式,意思是所有包含一个以上数字的字符串,诸如:‘2’,‘232’,‘232342434’……。
# x? 问号
问号表示左边的字符出现 0 次或 1 次。
$ grep '^[0-9]*\.\?[0-9]\+$' rfile |
我们来逐个分析这个正则表达式内的部分。[0-9]* 表示 0 个或若干个数字,随后紧接着是 \.,表示普通的句点,然后 \? 表示前面这个句点可以有 1 次,也可以没有,最后 [0-9]+ 表示若干个数字。
这个扩展正则表达式表示诸如:‘1’,‘12’,‘.1’,‘0.1’,‘0.12’,‘12.3’的字符串。
# Sed
sed 是流编辑器,编辑文本的方式类似 ed,但是能够用管道过滤文本,比普通编译器更高效。
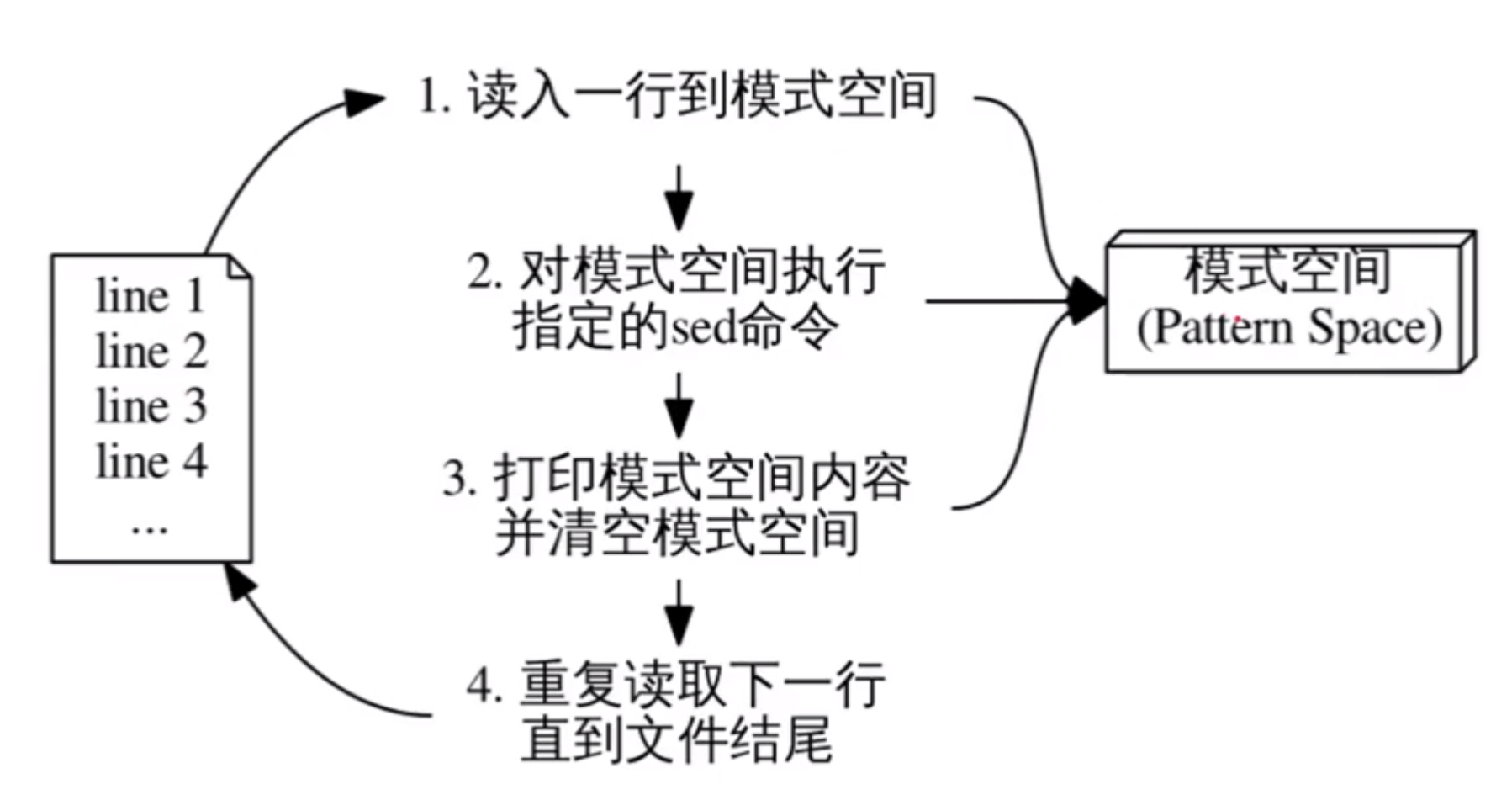
# 工作原理
sed 对文本文件的每一行进行循环处理:
sed 从输入流中读取一行,然后将其放入模式空间(通常是一块内存空间,即缓冲区),并删除末尾换行符。
从脚本文件中逐条执行命令,每条命令可以在前面附加地址作为条件,只有与条件匹配才执行命令。
除非使用 - n 选项,不然脚本执行结束后,将从模式空间中内容的末尾添加一个换行符,然后输出到标准输出。
回到 1,直至处理完所有的输入行。
除非使用特殊命令‘D’,不然每次循环之间的模式空间的内容将被清空。
![image]()
# 命令格式
$ sed [选项]... '脚本' 文件... | |
$ sed [选项]... -e '脚本1' -e '脚本2'... 文件... | |
$ sed [选项]... -f 脚本文件 文件... |
第一个,在文件前可以加脚本命令 (sed 命令) 对文本文件的每一行进行处理。
第二个,用 - e 选项指定多个脚本命令 (sed 命令) 对文本文件进行处理。
第三个,用 - f 选项指定一个脚本文件 (含若干 sed 命令的文本文件) 对文本文件处理。
# 常用选项
# -n
sed 默认在每个循环结束后打印出模式空间的内容,加上 - n 选项可以关闭自动打印。
假设有这样的文本文件:
$ cat students.db | |
1 mary female 19 100 | |
2 tom male 20 93 | |
3 susie female 20 97 | |
4 bob male 21 90 | |
5 alice female 19 93 | |
6 mike male 19 89 | |
7 jack male 20 78 | |
8 sam male 22 65 | |
9 william male 21 80 | |
10 tony male 23 90 |
$ sed '' students.db | |
1 mary female 19 100 | |
2 tom male 20 93 | |
3 susie female 20 97 | |
4 bob male 21 90 | |
5 alice female 19 93 | |
6 mike male 19 89 | |
7 jack male 20 78 | |
8 sam male 22 65 | |
9 william male 21 80 | |
10 tony male 23 90 |
没有 - n 选项将默认每次循环打印出模式空间的内容。
# -e SCRIPT
增加处理输入时要执行的命令 SCRIPT。
# -f SCRIPT-FILE
指定处理输入时要执行的脚本命令文件 SCRIPT-FILE。
# -i
原地修改源文件。
# -r、-E
使用扩展正则表达式 ERE,即正则表达式不需要反斜杠 \ 来表达扩展正则表达式元字符。
# sed 命令的地址选择条件
sed 命令可以在前面附加地址作为执行的条件,条件满足才执行命令。附加地址可以是行选择,也可以是范围选择。
# 行选择
n #第 n 行 | |
m~n #第 m+kn 行,如 1~2 表示所有奇数行,2~2 表示所有偶数行;m 是起点,n 是步长,k 是步数 | |
$ #末行 | |
/re/ #与指定的正则表达式匹配的行 | |
\%re% #同上,% 可换成其他字符,如 #,re 是正则表达式字符串 | |
/re/! #不与 re 匹配的行 |
# 范围选择
m,n #从第 m 行到第 n 行 | |
n,/re/ #从第 n 行到第一个与 /re/ 匹配的行 | |
/re1/,/re2/ #从第一个匹配 /re1 / 的行到第一个匹配 /re2 / 的行 | |
m,n! #从 m~n 行以外的行 |
# sed 常用命令
需要明确的是,选项和命令是不一样的。sed 的选项中有 - n,常用命令也有 n,它们的工作相似,但是本质是不一样的。
#
注释。
# q
退出 sed 编辑器。
$ sed '5q' students.db | |
1 mary female 19 100 | |
2 tom male 20 93 | |
3 susie female 20 97 | |
4 bob male 21 90 | |
5 alice female 19 93 |
5q 表示,在第五行默认打印结束后,退出 sed 编辑器。因此共打印 5 行。
# d
删除模式空间内的内容,并立即开始新的循环,将不执行此次循环内 d 之后的命令。
$ sed '/^$/d' students.db |
# p
打印当前模式空间的内容,通常与 - n 选项同时使用。
$ sed -n '1,$p' students.db | |
1 mary female 19 100 | |
2 tom male 20 93 | |
3 susie female 20 97 | |
4 bob male 21 90 | |
5 alice female 19 93 | |
6 mike male 19 89 | |
7 jack male 20 78 | |
8 sam male 22 65 | |
9 william male 21 80 | |
10 tony male 23 90 |
`1,$p` 的效果是,只要位于 1 到最后一行内,则打印该模式空间内容。-n 选项关闭了 sed 编辑器的默认打印,即避免了重复打印。
如果没有 - n 选项,则 sed 编辑器会默认打印一次,加上 p 命令就总共打印两次了。
$ sed '1,$p' students.db | |
1 mary female 19 100 | |
1 mary female 19 100 | |
2 tom male 20 93 | |
2 tom male 20 93 | |
3 susie female 20 97 | |
3 susie female 20 97 | |
4 bob male 21 90 | |
4 bob male 21 90 | |
5 alice female 19 93 | |
5 alice female 19 93 | |
6 mike male 19 89 | |
6 mike male 19 89 | |
7 jack male 20 78 | |
7 jack male 20 78 | |
8 sam male 22 65 | |
8 sam male 22 65 | |
9 william male 21 80 | |
9 william male 21 80 | |
10 tony male 23 90 | |
10 tony male 23 90 |
$ sed '$p' students.db | |
10 tony male 23 90 |
很明显,‘$p’打印末行。
# n
n 命令表示直接进入下一次循环,即下一行,将下一行的内容放到模式空间中。
#
命令组,用于对某个地址匹配要执行多条命令的场景。
$ sed -n 'n;p' students.db | |
2 tom male 20 93 | |
4 bob male 21 90 | |
6 mike male 19 89 | |
8 sam male 22 65 | |
10 tony male 23 90 |
命令组 {cmd1;cmd2;…} 与‘cmd1;cmd2;…’的作用是一样的。上面的命令,都会在奇数行执行‘n;p’命令,跳过奇数行,打印偶数行的内容,而且 - n 选项避免了重复打印。
上面的命令等价于下面两条命令:
$ sed -n {n;p} students.db | |
$ sed -n -e 'n' -n -e 'p' students.db |
# s、i、g
首先,介绍几个 s 命令的用法,以更好理解 s 命令。
$ cat well.txt | |
Sam reads well, sam writes well, sam sings well, sam dances well. | |
$ sed 's/sam/tom/' well.txt | |
Sam reads well, tom writes well, sam sings well, sam dances well. |
s 命令可以将第一个对应匹配的字符串进行替换。上面的例子,用斜杠分开两个字符串,将 sam 换成 tom。
这里不忽略大小写,如果要忽略大小写,用 i 命令。
$ sed 's/sam/tom/i' well.txt | |
tom reads well, sam writes well, sam sings well, sam dances well. |
如果想要一次性把所有的 sam 改成 tom,需要使用 g 命令。g 命令是全局的意思。
$ sed 's/sam/tom/ig' well.txt | |
tom reads well, tom writes well, tom sings well, tom dances well. |
当然,s 命令的反斜杠也可以换成井号 #。
$ sed 's#sam#tom#ig' well.txt | |
tom reads well, tom writes well, tom sings well, tom dances well. |
这个作用也是为了避免对字符串内的斜杠 / 进行转义的麻烦,同样有这样的例子:
$ echo /usr/bin/mkdir | sed 's/.*\///' | |
mkdir | |
# 等价于: | |
$ echo /usr/bin/mkdir | sed 's#.*/##' | |
mkdir |
如果指定第二个、第三个 sam 转换为 tom,可以:
$ sed 's#sam#tom#i2' well.txt | |
Sam reads well, sam writes well, tom sings well, sam dances well. | |
$ sed 's#sam#tom#i3' well.txt | |
Sam reads well, sam writes well, sam sings well, tom dances well. |
2 表示替换第二个匹配的字符串,3 表示替换第三个匹配的字符串,以此类推。
# &
& 符号常常用在 s 命令后的第二个正则表达式,作用是所代表的内容与第一个正则表达式一致。如:
$ cat costs.txt | |
this costs 23, and that costs 35 | |
$ sed 's/[0-9]\+/$[0-9]\+/' costs.txt | |
this costs $[0-9]+, and that costs 35 # 错误方式 | |
$ sed 's/[0-9]\+/$&/g' costs.txt | |
this costs $23, and that costs $35 |
# r
r 命令将在读取的某一行之后插入所导入的文件:
$ sed '3r file1' rfile |
上面的命令,从 rfile 这个文件中每读一行,就放到模式空间中,由于没有 - n 选项,因此会打印每一行。然而在第三行默认被自动打印后,将转向读取 file1 文件的内容,把 file1 文件的内容一行一行地放到模式空间中,然后默认自动打印,打印完 file1 的内容后,继续将 rfile 的每一行搬运到模式空间中,继续打印。
# w
w 命令将模式空间中与指定正则表达式匹配的行保存到一个文件中:
$ sed -n '/:\/\//w file2' rfile | |
$ cat file2 | |
https://www.baidu.com | |
http://www.jxnu.edu.cn | |
ftp://www.abc.net |
w 前的内容,是由一对斜杠括着的正则表达式。这个命令,将对 rfile 每一行进行判断,如果行内容与:// 匹配,则将该行保存到 rfile2 中。
# y
y 命令将第一个字符串的字符逐个对应地被第二个字符串的字符替代:
$ sed 'y/aeiou/xxxxx' file1 | |
fxrst lxnx fxlx1 | |
sxcxnd lxnx xn fxlx1 | |
thxrd lxnx xn fxlx1 | |
$ cat file1 | |
first line in file1 | |
second line in file1 | |
third line in file |
# =
等号 = 作用是打印该行行号,常常与地址选择条件中的行选择搭配使用。
$ sed -n '$=' rfile | |
133 |
# vim
vim 是一个含模式的文本编辑器。通过在终端输入 vim,可以直接进入 vim 中。
# 三种基本模式
vim 有三种模式:Normal 正常模式、Insert 插入模式、Command-Line 命令行模式。其中,正常模式是最基本的模式,在终端输入 vim 命令后进入 vim 编辑器内的模式就是正常模式。
正常模式是最基本的模式,其他模式通过按下 ESC,可以返回到正常模式。正常模式也可以使用特定的按键进入其他模式。按下 i 可以进入插入模式、按下冒号:进入命令行模式。
# 入门操作
$ vim hello-vim.txt |
在终端下输入 vim 后面跟上文件,可以在 vim 编辑器中打开这个文件。
:wq |
保存退出。(开头带:就是命令行模式)
:q! |
强制退出!
G(Normal) |
将光标移动到最后一行。
o(Normal) |
在下面打开新行并进入 insert 模式。
ZZ(Normal) |
直接保存退出。
# 光标移动
在 Normal 模式下有许多快捷键可以快速移动光标。基本的四个光标移动快捷键如下图:
^ | |
| | |
<- h j k l -> | |
| | |
v |
除此之外,还有其他的快捷方式:
5k # 光标上移 5 行 | |
10l # 光标右移 10 个字符 | |
^ # 光标移动到行首非空白字符 | |
0 # 光标移动到行首 | |
$ # 光标移动到行尾 |
翻页:
Ctrl-b # 上一页 | |
Ctrl-f # 下一页 |
跨行快速移动:
15G # 光标移动到第 15 行 | |
G # 光标移动到最后一行 | |
gg # 光标移动到第一行 |
光标撤销与前进:
Ctrl-o # 光标回到上一位置 | |
Ctrl-i # 光标前进到下一位置 |
单词与句间移动:
b # 光标移动到单词开头 | |
w # 光标移动到下一个单词 | |
e # 光标移动到单词尾部 | |
( # 光标移动到上一句 | |
) # 光标移动到下一句 | |
3( # 移动到前 3 句 | |
{ # 光标移动到上一段 | |
} # 光标移动到下一段 | |
% # 光标移动到与该括号匹配的另一个括号 |
# 编辑操作
在 Normal 模式下也有快捷键可以快速进入插入模式编辑文本。功能可视为光标移动 + 插入模式的组合体。
I # 在行首插入一行 | |
a # 在光标后插入 | |
A # 在行尾插入 | |
o # 在光标下方插入新行 | |
O # 在光标上方插入新行 | |
r # 在 Normal 模式下不进入插入模式实现单字符替换 | |
s # 删除光标所在字符并进入插入模式 | |
S # 删除当前行并进入插入模式 | |
x # 删除光标所在字符,不进入插入模式 | |
X # 删除光标前一个字符,不进入插入模式 |
# 可视模式
Visual 模式我理解为是一个可供选中大块文本块的模式。
# 进入 Visual 模式:
v # 字符 visual 模式 | |
Shift-v # 行 visual 模式 | |
Ctrl-v # 块 visual 模式 | |
<ESC> # 退出 visual 模式 |
字符 visual 模式。光标经过的地方将会被选中入反白区,也就是被选择区。这时候用 $、0、^、hjkl 等移动光标会改变被选中区域的大小以及被选中的内容。
行 visual 模式。光标的移动将会进行一行一行的选择。,反白区域的末尾不会出现在行中间。
块 visual 模式。光标的移动会选中一个矩形区域。有点类似于 windows 桌面用鼠标框选内容的效果。

# 编辑 visual 模式
选中文本块后,被选择的文本将反白显示。这时候可以用这四个快捷键快速编辑所选中的文本。
c # 修改 | |
d # 剪切 | |
y # 复制 | |
p # 粘贴 |
# 其他编辑操作
Normal 模式下还有其他的编辑操作。
~ # 转换当前字符的大小写 | |
J # 把当前行与下一行合并为一行 |
介绍一个缩写操作:
:ab nos network operating system # 定义 nos 为 network operating system 的缩写。 | |
输入nos并按空格 # 使用缩写 nos |
# 进程管理
# 一些基本概念
每个进程都有一个 PID 以标志进程的唯一性。打印进程时,
# 一些常用命令
$ ps aux # 打印进程及 PID | |
$ pstree # 打印进程树 | |
$ pstree -p # 打印进程树,同时打印进程的 PID | |
$ kill [进程号] # |
# shell 脚本编程
# 执行脚本方式
方法一:如果nu是bash文件,那么: | |
$ sh nu | |
可以运行改bash脚本 | |
方法二:可以通过给bash文件赋予执行权限 | |
$ chmod +x nu | |
$ ./nu | |
这样也可以运行 |
# 注释与 #!
通过井号可以直接打注释,通过行首是 #! 的语句,可以指定执行程序。
#! /bin/bash | |
bash语句...... | |
# 注释某行 |
/user/bin/bash 是 bash 脚本的执行程序,bash 脚本需要通过这个执行程序才能执行。
# 参数设置
在 bash 脚本文件中,可以通过如下方式指定 bash 脚本执行时的参数,如下是一个 bash 脚本文件。
#! /bin/bash | |
pr -t -$1 | |
pr -t -$2 | |
pr -t -$3 | |
dollar符后面接上数字表示第几个位置参数。 |
当然,可以通过这种方式表示所有参数。
#! /bin/bash | |
chmod +x $* | |
星号的方式表示所有参数。 |
以下是与位置参数有关的特殊变量:
$0 # 当前脚本路径名 | |
$1, $2, ..., $9 # 位置参数 | |
${10} # 第 10 个位置参数 | |
$* # 所有位置参数 (不包括 $0) | |
$# # 位置参数个数 (不包括 $0) |
# 命令替换
bash 脚本通过 ` `、$() 的方式进行命令替换,如下方式:
#! /bin/bash | |
dirname 'which route' | |
# 假设 route 是一个文件,which 获得该文件的路径 | |
dirname $(which route) |
两种方式输出一致.。
# bash 脚本调试方法
在某行 bash 命令的行首加入 echo。
# 网络连接配置
# 基本知识
linux 通过 NetworkManager 进行网络配置,命令行工具有 nmcli。
一个主机可能有多个网络连接设备,每个设备的信息与配置存放在单独一个配置文件中。这些配置文件都位于一个文件夹中:/etc/sysconfig/network-scripts,而该文件夹内的 ifcfg-<接口名称> 文件记录了这些网络设备的配置信息。
# VirtualBox 虚拟机配置网络之 host-only + 网络共享法:
因为我在配置 Linux 虚拟机时,被网络配置折磨地死去活来,而且各种方法层出不穷,为了保证以后更加熟练,这里进行总结。
# 第一步:配置虚拟机 host-only 网卡,并设置虚拟机网络模式为仅主机模式
首先,将 Linux 虚拟机地网络设置成 host-only 仅主机模式: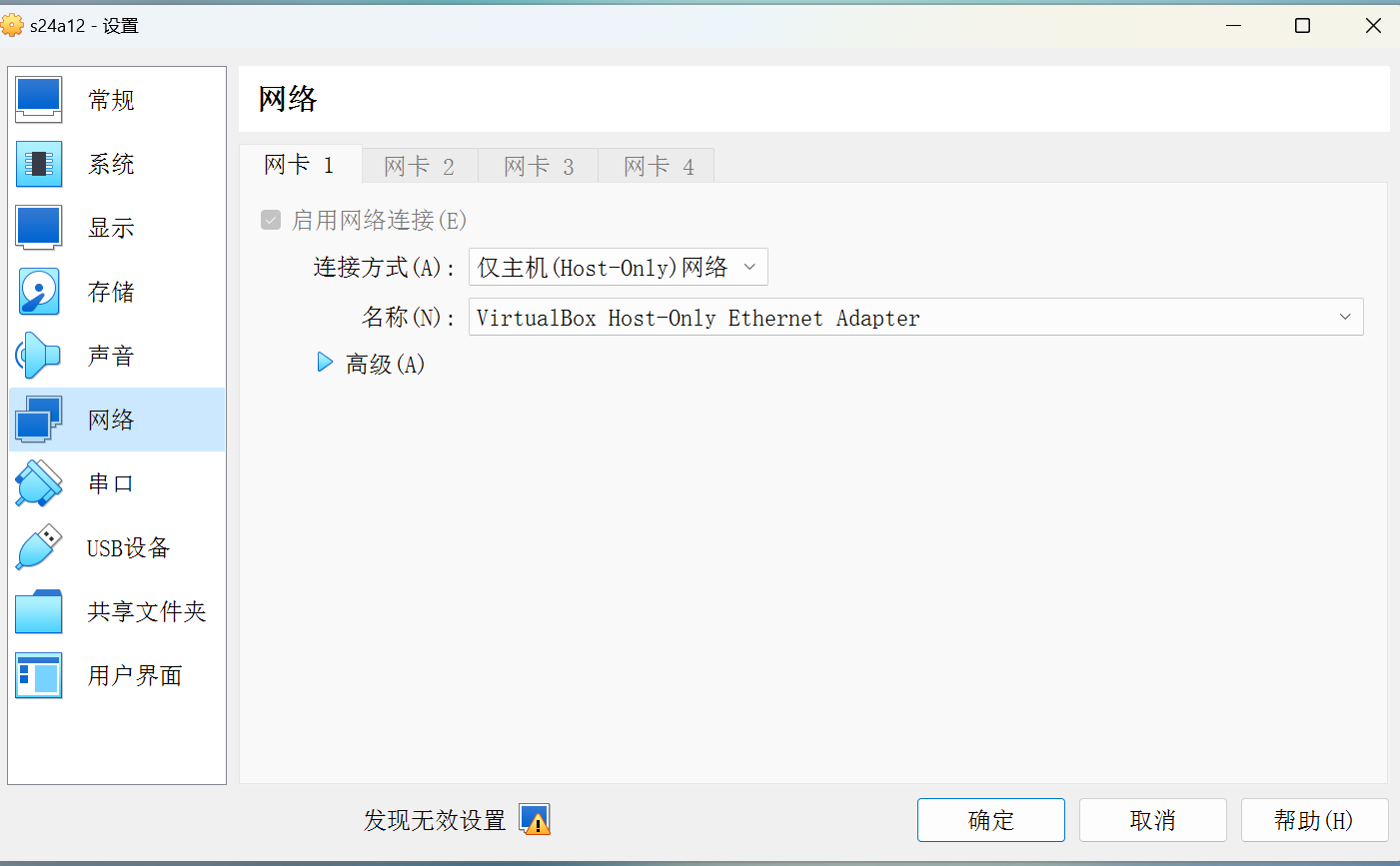
以及确保 VirtualBox 的管理器设置了网卡: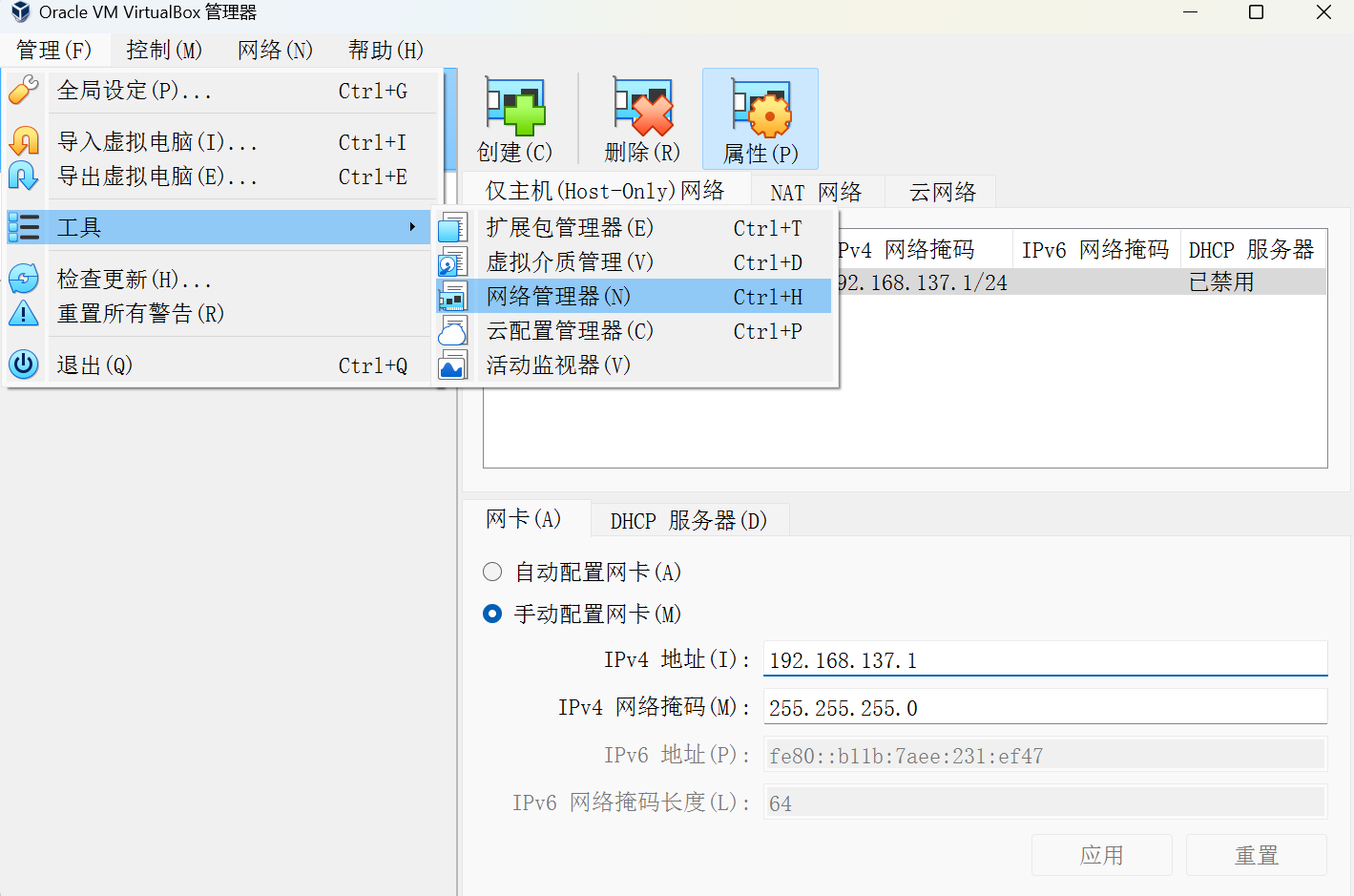
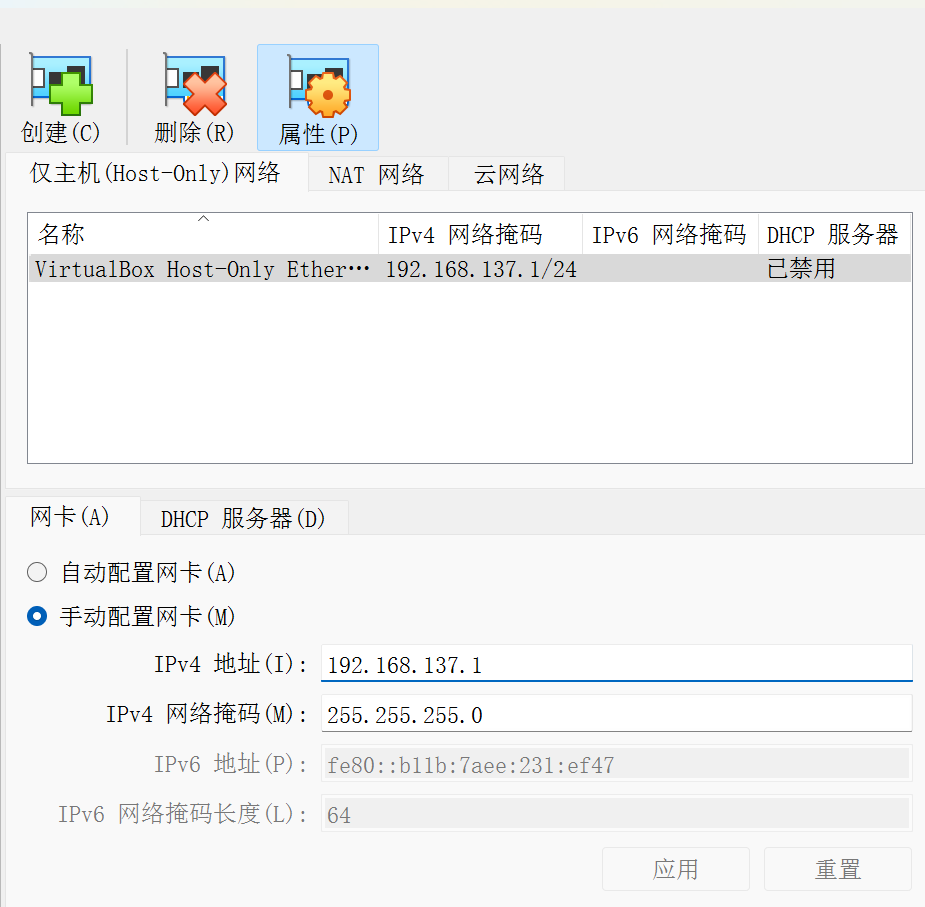
确保有 Host-only 网卡。没有就创建一个就好了。
# 第二步:通过主机网络共享,为 host-only 网卡分配 ip 地址。
这时候其实不能上外网。我们要把主机的 WLAN 与虚拟机的以太网进行共享:
右键网络图标,打开网络和 Internet 设置:
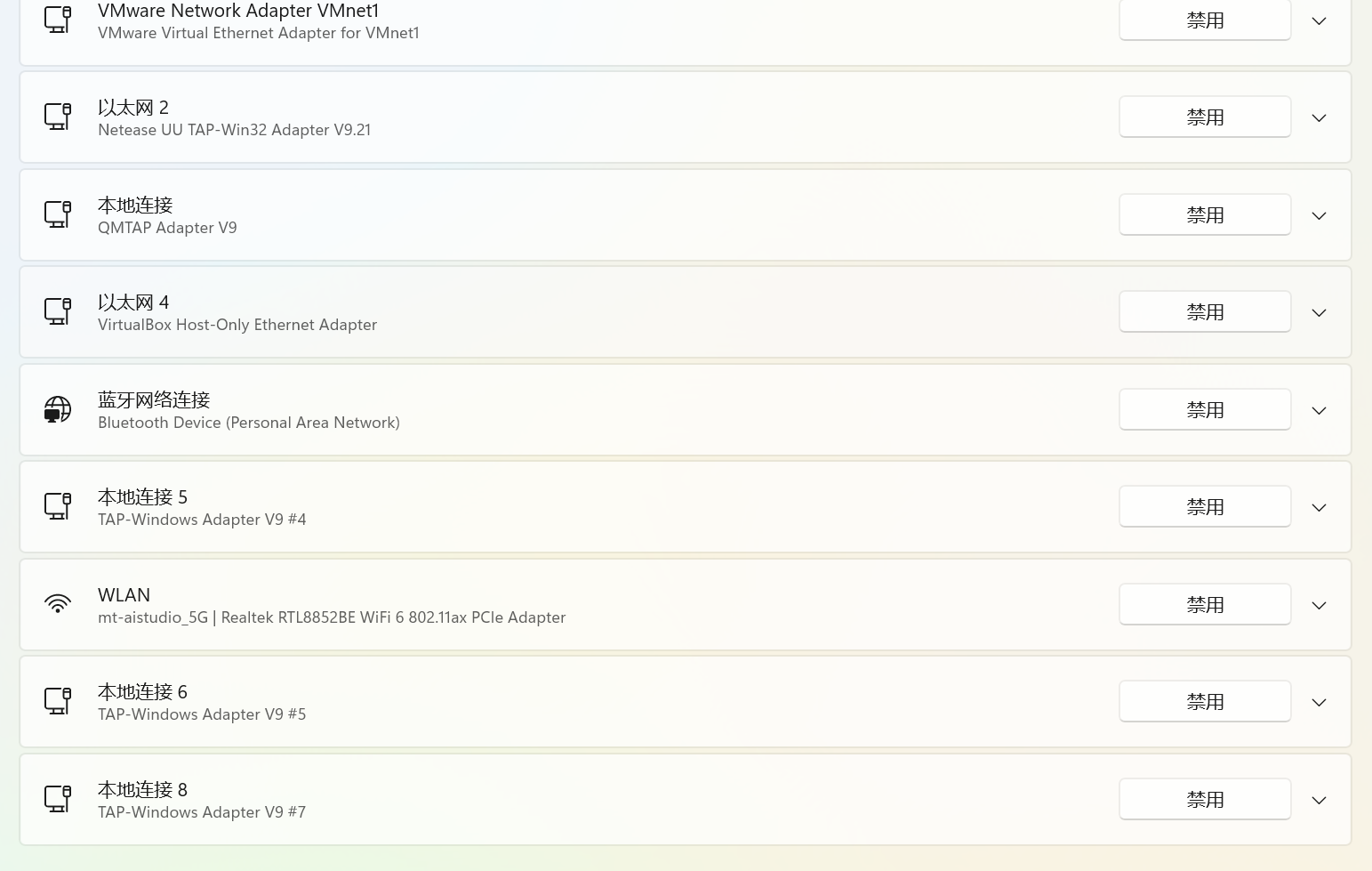
很明显看到有一个以太网 4,这个是前面配置好的 host-only 网卡。
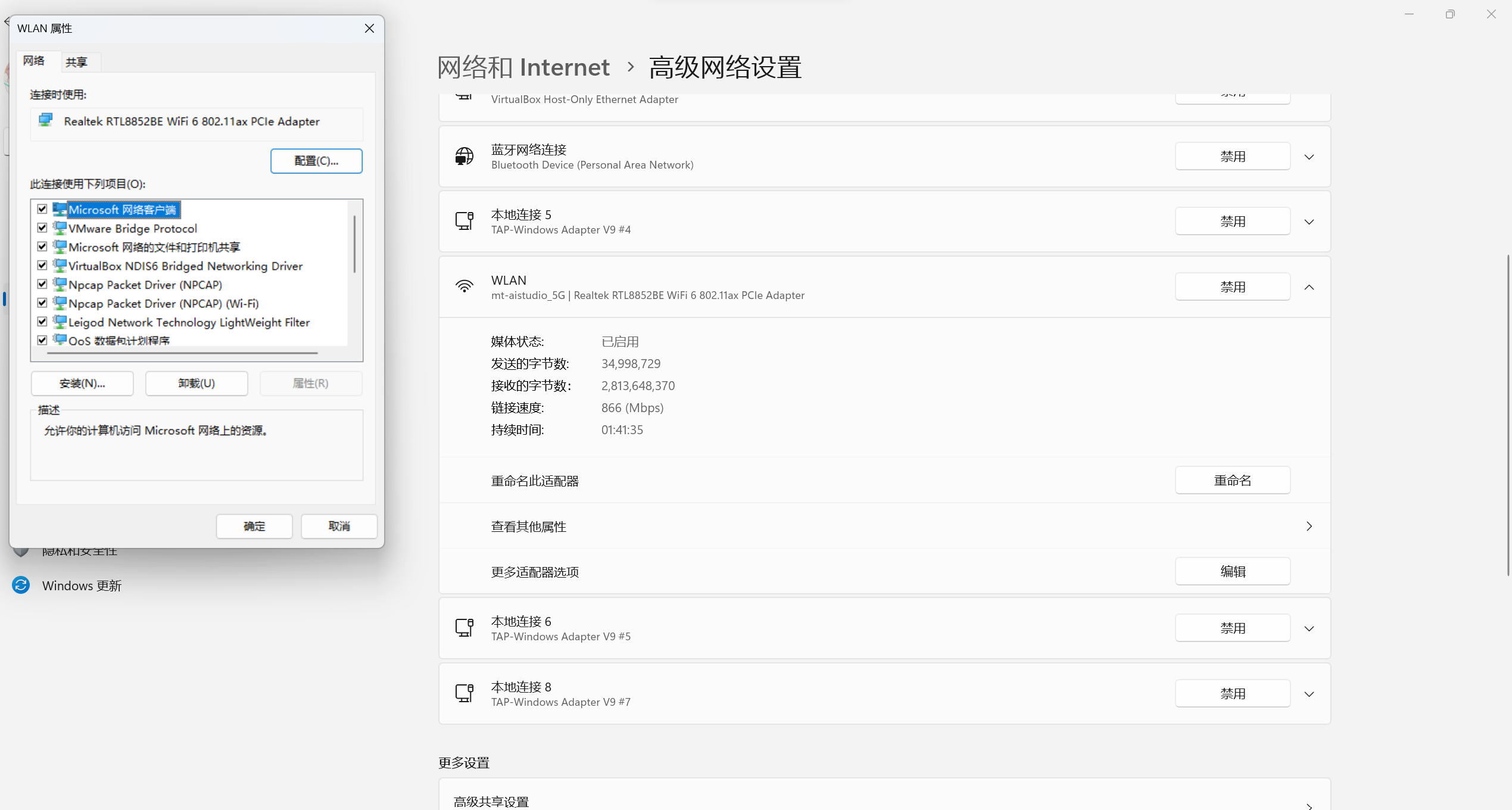
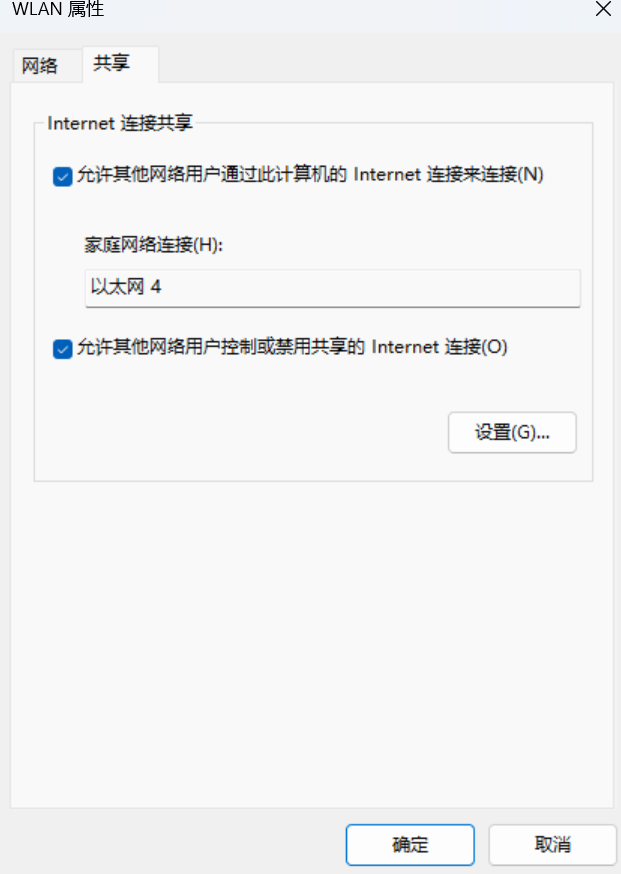
选择主机现在用的网络 WLAN-> 更多适配器选项 -> 编辑,打开到 WLAN 属性。点击共享,勾选允许其他网络用户通过此计算机的 Internet 连接来连接,然后在家庭网络连接中选择上面的 host-only 网卡。然后确定。
这时候,windows 会自动给 host-only 网卡分配一个 ip 地址:192.168.137.1,默认网关被设置为主机 WLAN 使用的 IP 地址。
打开 windows 的 cmd,输入 ipconfig。

以我的电脑和网络环境为例,这里主机使用的网络 WLAN,IP 地址为 192.168.31.26,默认网关是 192.168.31.1。
可以看到虚拟机网卡 —— 以太网 4 的 ip 地址与默认网关: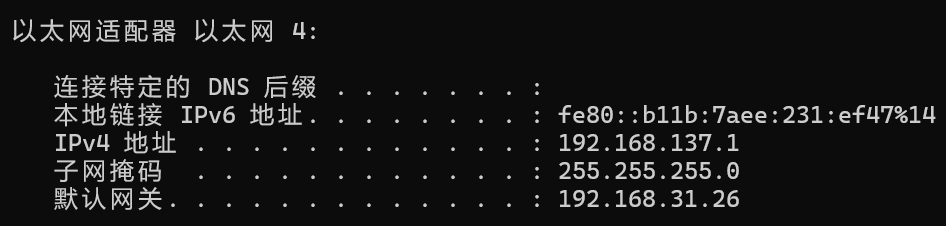
IP 地址被分配到默认的 192.168.137.1,默认网关是 192.168.31.26。这个默认网关实际上就是主机的 IP 地址。
进入 VirtualBox 管理器的网络管理器,确保 host-only 网卡被设置为被分配的 ip 地址。
# 第三步:进入虚拟机设置虚拟机的 IP 地址
进入虚拟机。设置网络。
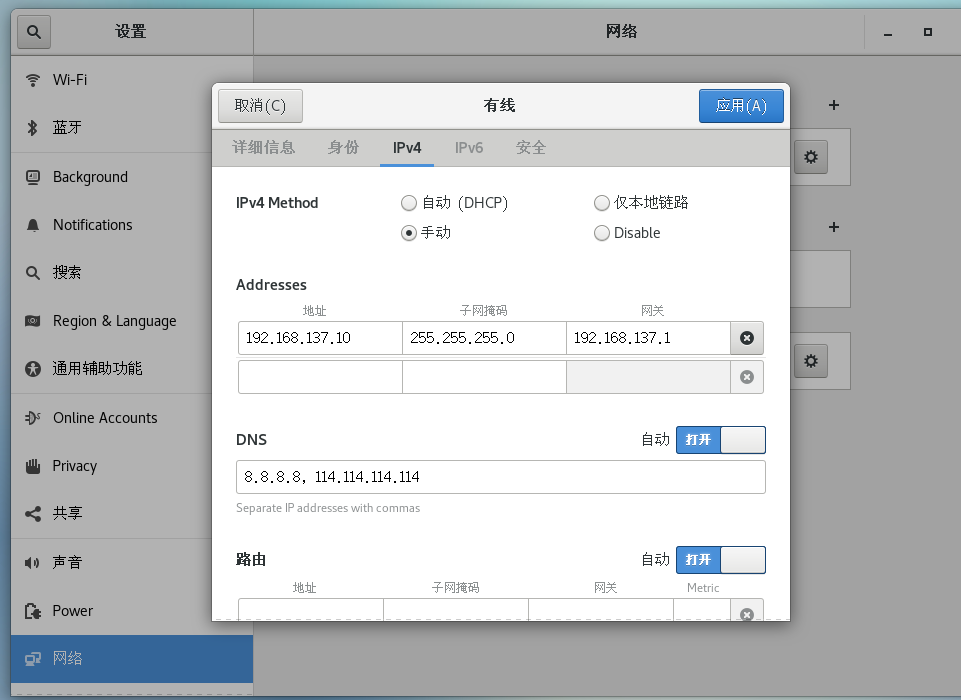
在 ipv4 部分,选择手动模式。
Addresses 部分的网关设置为 host-only 网卡的 ip4 地址,也就是上面以太网 4 的 ip4 地址。填好子网掩码。地址部分,四个字段,前三个字段必须与网关值一样,最后一个地址字段可以随便设置。这样,虚拟机的 ip 地址与虚拟机网卡的 ip 地址处在一个网段。
# 第四步:检查 ping 通性
重启网络。尝试 ping www.baidu.com ,发现 ping 通。
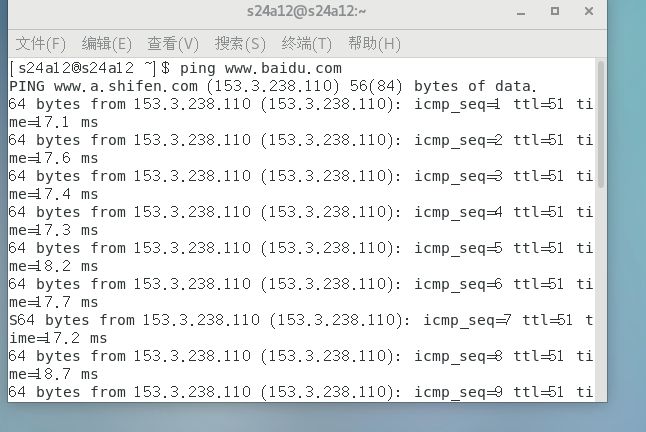
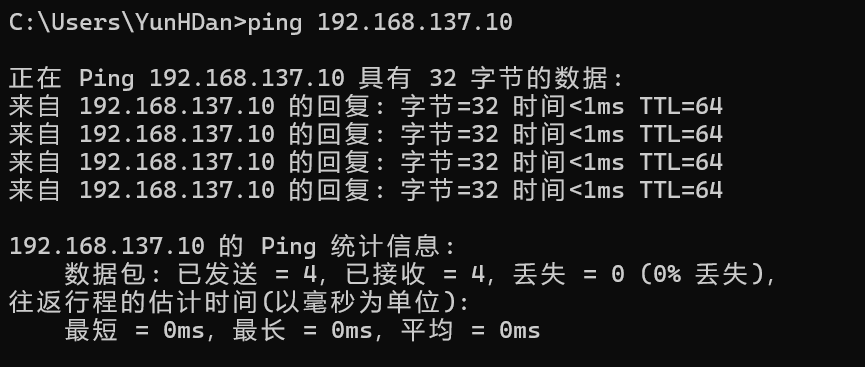
主机能 ping 通虚拟机。
但是虚拟机无法 ping 通主机。
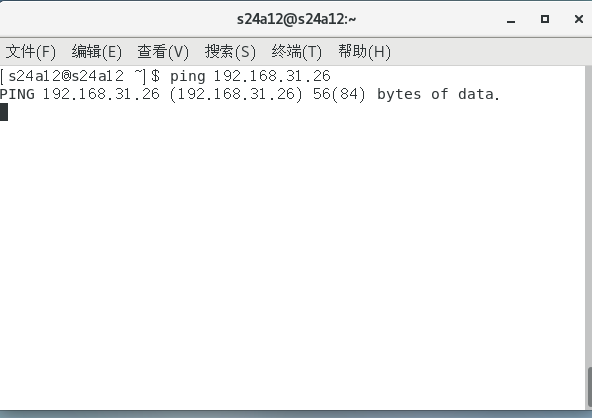
虚拟机也无法 ping 通 host-only 网卡:
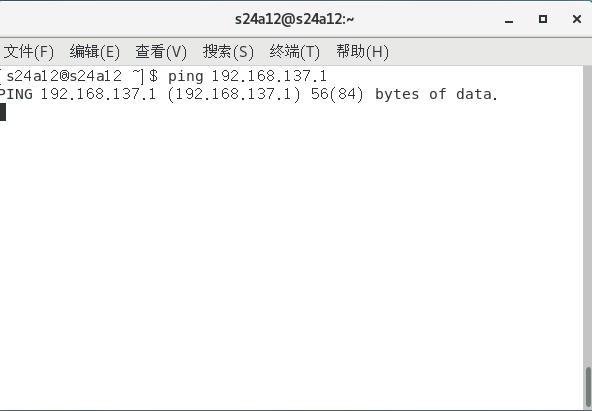
但是,虚拟机可以 ping 通主机的网关:
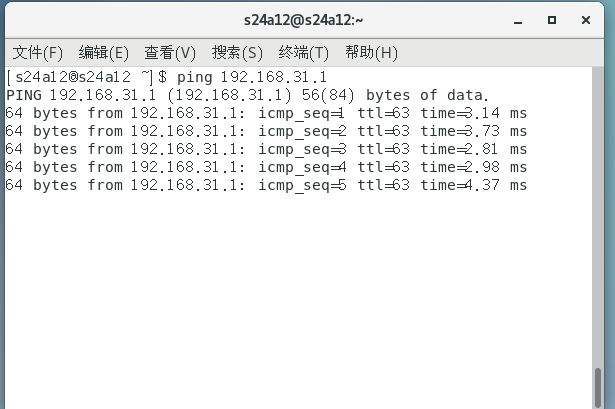
这是因为主机的网关处于外网。所以,这时候配置完的虚拟机,可以上外网,但是无法 ping 通主机的网络,而主机能够 ping 虚拟机。
# 另外
如果不想使用 windows 默认给 host-only 网卡分配的 ip 地址,可以自己到 host-only 网卡的更多适配器选项中设置:
打开以太网 4 的更多适配器选项: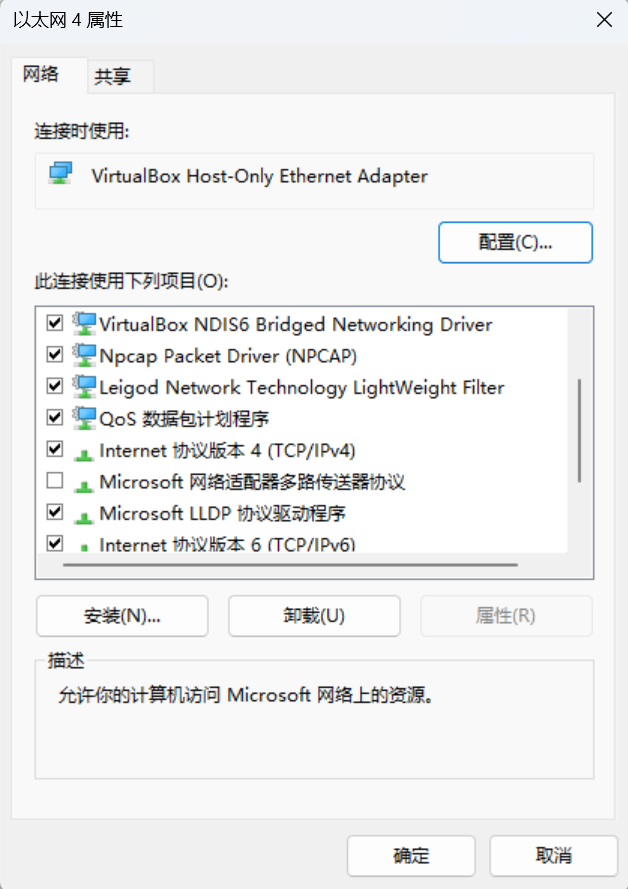
双击:Internet 协议版本 4 (TCP/IPv4)
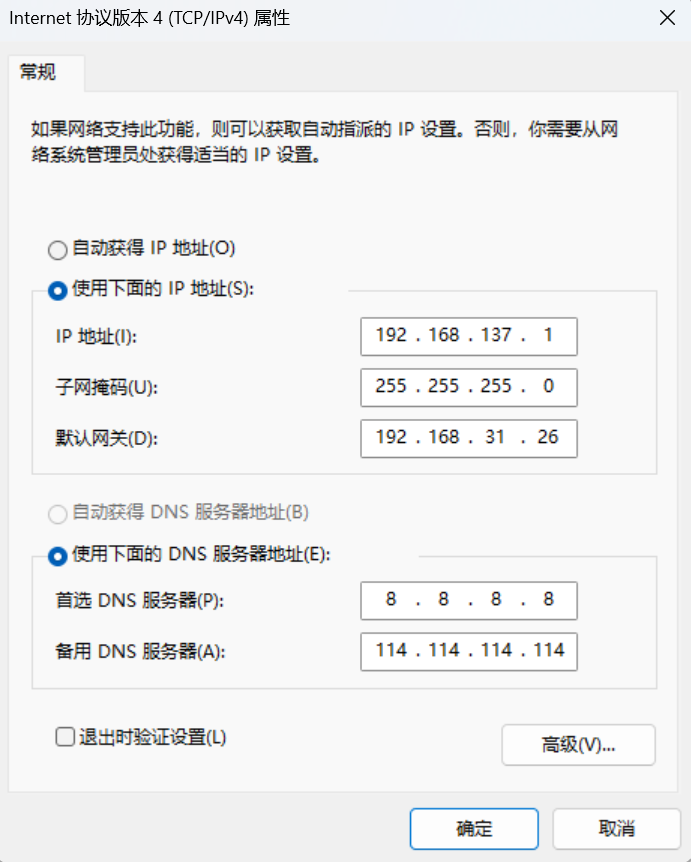
手动设置 IP 地址,但是默认网关必须是主机的 IP 地址。(上面我还在使用默认分配的 ip 地址,主要是懒得再折腾)
# 查看某个文件夹下有多少个文件
配合 ls 和 wc 使用:
ls /path/to/source/folder | wc -l |
# export PYTHONPATH="$PWD:$PYTHONPATH"
这是一个通过 PYTHONPATH 手动指定项目根目录的命令。
以深度学习项目 Retinexformer 为例,这个项目文件夹内包含了训练的代码 train.py ,以及模型架构文件等。
有时候直接在终端通过 python train.py 的绝对路径会报一些代码文件中的库引用错误,但是你反复检查了路径,觉得代码里导包的方式没问题。
这时候你就可以先通过 cd 命令进入项目文件夹中,然后再执行这个 export 命令手动指定项目根目录:
> cd Retinexformer | |
> export PYTHONPATH="$PWD:$PYTHONPATH" |
# 当 Linux 内存不足时,扩大交换空间
首先要处理一下现有的交换文件:
# 查看当前启用的交换空间 | |
sudo swapon --show | |
# 如果存在 /swapfile,先关闭交换文件 | |
sudo swapoff /swapfile | |
# 删除旧的交换文件 | |
sudo rm /swapfile |
然后创建一个更大内存的交换文件:
# 创建 8GB 交换文件 | |
sudo fallocate -l 8G /swapfile | |
sudo chmod 600 /swapfile | |
sudo mkswap /swapfile | |
sudo swapon /swapfile |
# 后台运行终端命令
使用 nohup 命令可以使得终端命令放到后台运行,格式参考如下:
nohup [instruction] > [**.log] 2>&1 & |
# 查看子目录占用
du -h --max-depth=1 | sort -rh |
这个方法会显示当前目录下所有一级子目录的磁盘使用情况,并按照从大到小的顺序排列。
| 命令部分 | 作用 |
|---|---|
du | 估算文件或目录的磁盘空间使用情况。 |
-h | 以人类可读的格式显示大小(例如:、)。 |
--max-depth=1 | 关键参数:只显示当前目录下的第一级子目录和文件(即不递归深入)。 |
sort | 对输入行进行排序。 |
-r | 逆序(Reverse)排列,即从大到小排列。 |
-h | 启用人类可读格式(Human-readable)的数值比较(例如:能正确比较 和 )。 |
# Line 2: $'\r': command not found—— 跨系统文本传输问题的解决办法
Windows/DOS 系统使用 \r\n (回车 + 换行) 来表示一行的结束。Linux/Unix 系统只使用 \n (换行) 来表示一行的结束。当你把一个在 Windows 或 DOS 下创建的脚本文件传到 Linux 环境中运行时,Shell 会把每行末尾的那个额外的 \r 字符(在终端显示为 ^M )当作是命令的一部分。你需要将脚本文件中的 DOS 换行符转换成 Unix 换行符。最常用的工具是 dos2unix :
# For Debian/Ubuntu | |
apt-get install dos2unix | |
# For CentOS/RHEL | |
yum install dos2unix |
假设有一个路径为 scripts/generate_instructions.sh 的文件,现在对其进行转换:
dos2unix scripts/generate_instructions.sh |
