[TOC]
# 基本关系
集群下管理着多个开发机,开发机是用户使用计算资源的基本单位。每个集群有自己的共享存储卷、块存储卷以及对象存储卷。不同集群的存储不共享。
共享存储卷一般存放数据集之类的大型训练数据,可挂载到多个开发机,块存储一般只挂载到一个开发机。对象存储主要是存海量非结构化数据,如图片、音频、视频、文本等。
# 开发机使用
介绍两种常用的使用方式。方式一,开机后使用开发机自带的 Jupyter,即点击 JupyterLab。在 JupyterLab 里可以通过这个按钮上传文件:
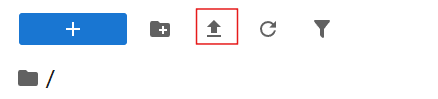
然后红框左边的按钮是创建新的目录,红框右边是刷新,蓝色加号是打开新的 Jupyter 页面。
方式二,用 ssh+VSCode 连接。在 VSCode 搜索如下两个插件:
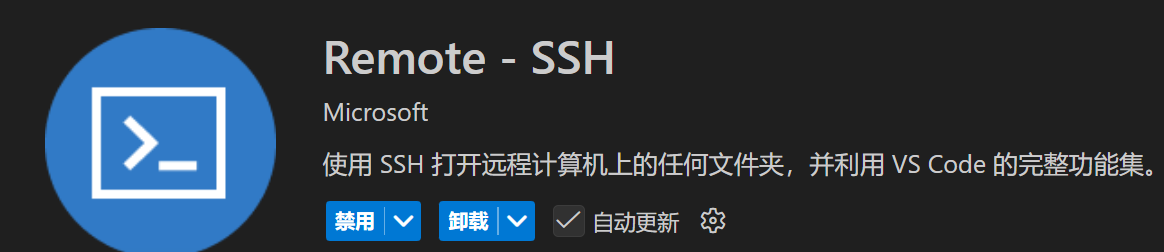
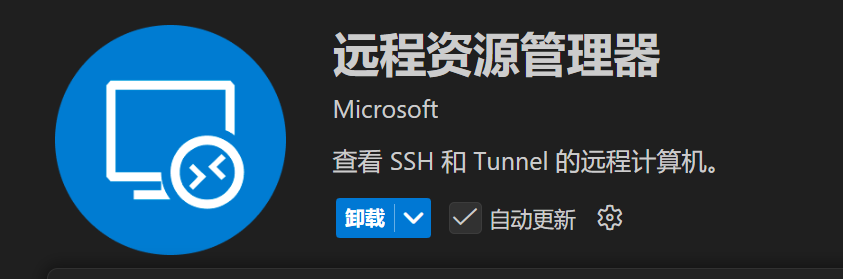
安装完毕后重启 VSCode,点击左侧的远程资源管理器打开 ssh 服务器选择栏:
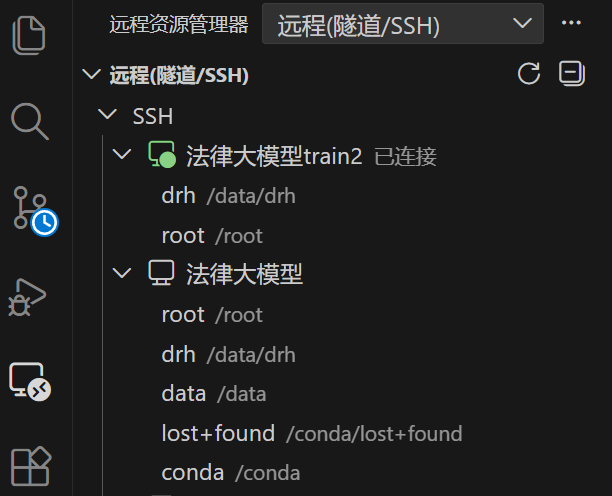
点中加号,增加远程服务器:

打开英博云的开发机页面,点击开发机的远程连接,复制登陆方式命令: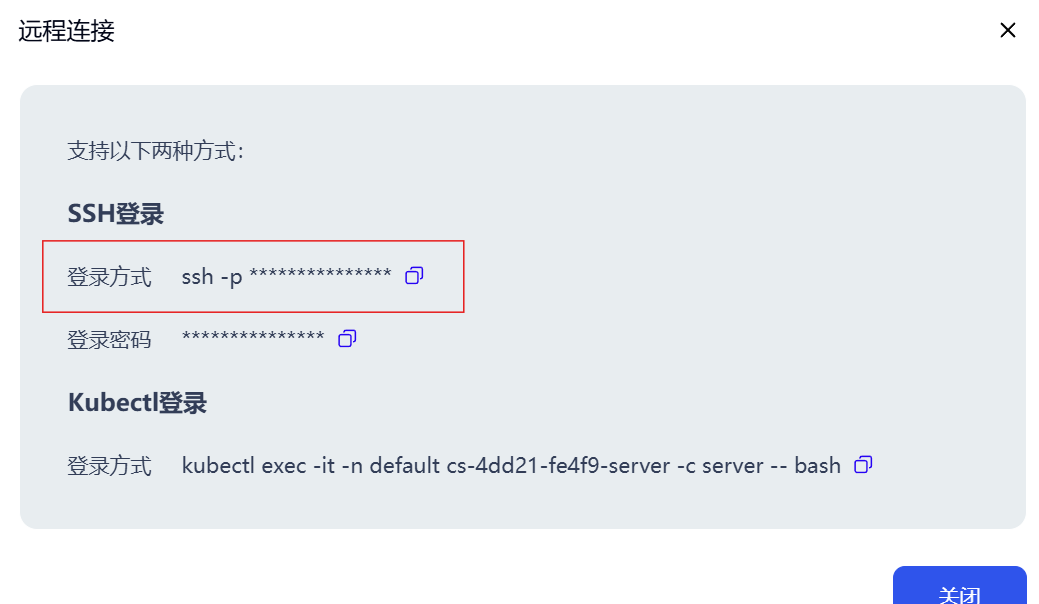
粘贴到弹窗:
选择要更新的 ssh 配置文件,没有就自己创建一个:
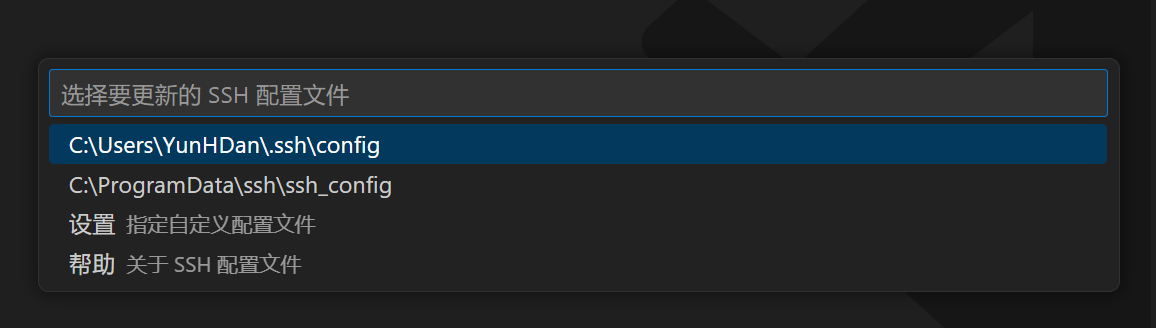
在弹出的配置页面中配置 ssh:
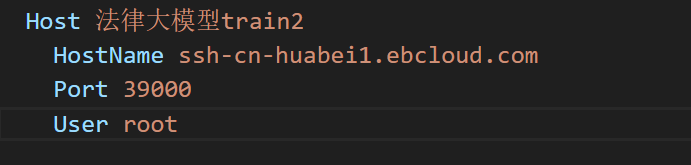
Host 是远程服务器名字,可以自己取。假如我们复制的 ssh 登录方式是: ssh -p 39000 root@ssh-cn-huabei1.ebcloud.com ,那么 HostName 就是 @后面的内容,Port 是 ssh - p 后面的数字,User 是 @前面的 root。
保存后退出,点击箭头进入连接:
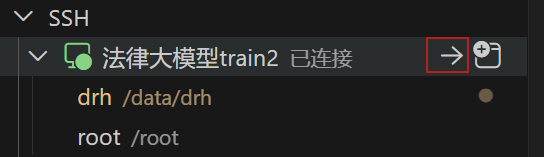
会要求选择远程平台类型,选择 Linux,然后会弹出有指纹,点击继续后进入密码输入,复制英博云开发机远程连接的登录密码然后粘贴过去即可连接:
# 开创环境盘
系统盘默认挂载到 root 目录,进入 root 目录会看到 miniconda3 已经安装好,之后 conda create 的虚拟环境会安装到 miniconda3/envs 中,pip 的缓存也在 root 目录下。
然而系统盘只有 30G,将来创建更多虚拟环境时,这点空间是肯定不够的。因此推荐将 pip 缓存以及虚拟环境的位置更改到其他地方。
我们在英博云开一个块存储卷,专门放置环境:
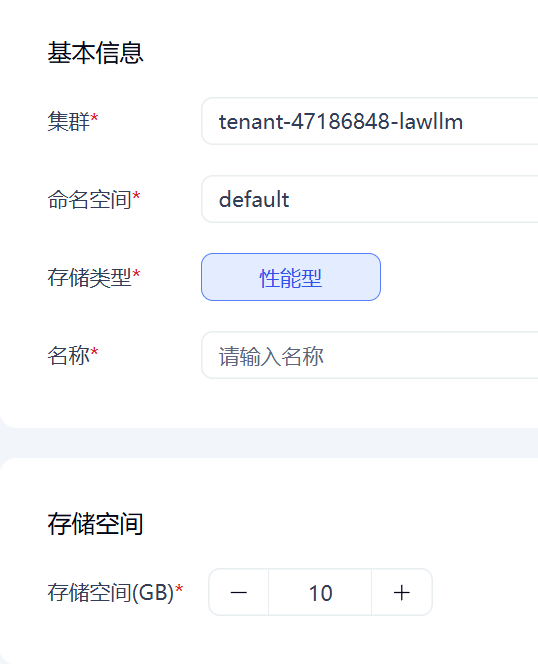
存储空间可以取大些,比如 64G、128G。然后到开发机中更改实例配置,下滑到存储配置,在块存储卷中挂载你新开的存储卷,然后挂载路径自定,之后在这个路径放东西就相当于放到这个新盘。
为什么要开一个新盘放环境已经讲清楚了。那么为什么选择块存储卷而不是共享存储卷放置环境?这是因为一个块存储卷只能挂载到一个开发机,也就是说如果你把这个新盘挂载到你的开发机,那么其他开发机就无法再访问这个盘的数据,就能够避免了环境被其他开发机删除的情况,而且允许了不同的开发机有不同的虚拟环境名。
如果已经开过一个环境盘,还有空间的话,那就不用再开了,这里是针对新创建机器的。
# 环境配置
# 更改 conda 的环境存放位置
进入根目录下的 conda 目录(通常叫 miniconda3 或者 anaconda3),在该级目录下找到 .condarc 这个文件,添加如下内容:
envs_dirs: | |
- /data/envs |
/data/envs 是你自定义的存放虚拟环境的位置,一般是在前面新盘的挂载路径下。保存后,以后创建虚拟环境就能自动在这个目录下创建了。同时,你可以把虚拟环境 env 目录移动到这个自定义的位置,conda 也会识别到虚拟环境。
这样,多个虚拟环境就会安装到块存储卷中,避免了系统盘的臃肿。
# 更改 pip 缓存的存放位置
pip 的缓存是全局的,也就是说所有的虚拟环境的 pip 缓存都将存放到一个地方,一般默认存放到根目录 root 下的 .cache 目录下。这时可以通过如下命令更改 pip 缓存的存放位置:
pip config set global.cache-dir "/home/your_path" |
或者进入根目录下的 .config/pip 目录,找到 pip.conf 文件,打开可以发现有如下内容:
[global] | |
cache-dir = /data/pip_cache |
在 cache-dir 字段更改为自定义的路径位置即可。
如果你想恢复默认设置,可以使用以下命令:
pip config unset global.cache-dir |
同样,如果之前已经更改过了配置的开发机,就没必要再更改了。
# 共享存储卷
确保你的开发机做好了共享存储卷的挂载,打开开发机的实例配置,下滑到存储配置:

添加共享存储卷后,为其定义挂载路径,这样之后代码和数据集可以放到开发机的这个路径下。
关于共享存储卷,建议每个人用自己的拼音名来命名自己的文件夹,然后在这个自己的文件夹下放自己的数据,这样便于查找,防止冲突。
# 通过 huggingface_cli 下载模型和数据集
除了直接到网页端点击下载按钮之外,还可以在终端用命令行的方式下载数据集和模型。
首先应该安装 huggingface_hub 工具:
pip install -U huggingface_hub |
huggingface-cli 已经弃用,huggingface-cli 已经更新为 hf 命令。关于 hf 命令有哪些变化,可以考虑学习这篇文章:https://zhuanlan.zhihu.com/p/663712983?s_r=0。
在 Windows,你可以依次执行:
$env:HF_ENDPOINT = "https://hf-mirror.com" | |
hf download --resume-download [model name] --local-dir [save location] |
在括号内替换为具体的内容。model name 是 huggingface 某个仓库具体的名字,比如下面的 ShengbinYue/DISC-Law-SFT 。save location 则是保存到本地的目录名。

下载数据集的命令则是在前面下载模型的命令增加 --repo-type dataset 参数。在 Linux 平台,你可以考虑把执行 $env:HF_ENDPOINT = "https://hf-mirror.com 换成执行:
export HF_ENDPOINT="https://hf-mirror.com" |
$env:HF_ENDPOINT = "https://hf-mirror.com"和 export HF_ENDPOINT="https://hf-mirror.com" 的目的就是在于解决国内访问 huggingface 服务器失败的问题。设置这命令就是提供一个镜像以便更快地访问,这个是官方的镜像,速度快。
# 加速访问
如果你发现上面的方法下载速度还是很慢,你可以参考下面的做法。
# hfd+aria2
首先下载 hfd 和 aria2c:
wget https://hf-mirror.com/hfd/hfd.sh | |
chmod a+x hfd.sh | |
sudo apt-get install aria2 | |
sudo apt-get install git-lfs |
hfd 这玩意默认安装到当前路径下。
设置环境变量:
export HF_ENDPOINT=https://hf-mirror.com |
下载模型 / 数据集:
./hfd.sh [model/datasets] --tool aria2c -x 8 |
# 一步到位 —— 英博云内置加速服务
确保安装好了 hfd 和 aria2c,没有就看上面先安装好。
此时不设置环境变量 export HF_ENDPOINT=https://hf-mirror.com 。在终端输入命令:
source /public/bin/network_accelerate |
这个命令可以在当前终端打开英博云的加速服务,支持访问 github、huggingface、wandb 等。
取消加速的命令可参考:
source /public/bin/network_accelerate_stop |
设置了加速后,再输入下载命令:
./hfd.sh [model/datasets] --tool aria2c -x 8 |
