Low-Level CV
这篇博客是无限长的,随着阅读论文数量的增多,将会越来越长。这篇博客的目的与定位就是简介描述的,精简提炼所读论文中的创新点,贡献,个人认为的不足。无详解,只是一个摘要的作用。有时候,我会把某篇论文的详解做出来。当然,看心情和时间吧。能够提炼出要点,说明这篇文章的思想才算是完全吸收。做精炼论文是好习惯,要养成。
Low-Light Image Enhancement
2024 CodeEnhance: A Codebook-Driven Approach for Low-Light Image Enhancement(CodeEnhance)
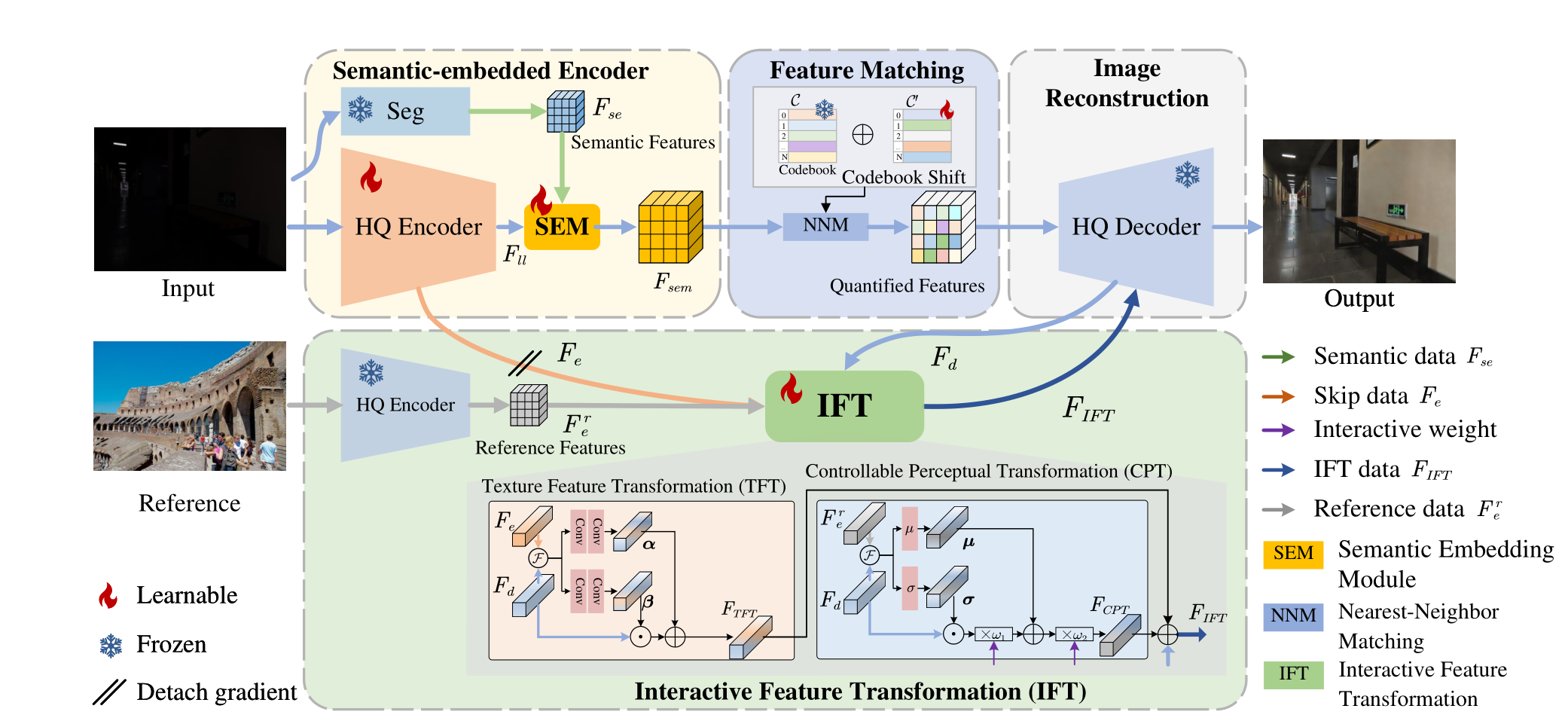
贡献(提出哪些解决方法)
- 利用
codebook从High-Quality图像中学习先验。 - 在
Unet编码器端并行设计预训练的语义信息提取网络SEE,在编码器末端设计一个语义信息融合模块SEM,将语义信息与图像特征融合。 - 因为
codebook学习的先验所用数据集和第二阶段训练所用数据集不同,设计了一个codebook偏移机制CS处理引入codebook产生的数据分布偏移问题。 - 在预训练的解码器末端附加一个特征转换模块
IFT。一方面,利用参考图像Reference丰富解码器High-Quality解码图像的信息,另一方面,在IFT内的CPT加入两个人为设计的以实现可控式图像提亮。
创新(如何解决提出的问题,.ie作者实验的底层逻辑)
很明显知道这篇低光的论文是基于
Towards Robust Blind Face Restoration with Codebook Lookup Transformer这篇文章的工作,所以创新是相对于Towards Robust Blind Face Restoration with Codebook Lookup Transformer的创新。我们可以把Towards Robust Blind Face Restoration with Codebook Lookup Transformer称为base work
- 在
encoder并行引入一个语义感知模块,与encoder通过一个语义融合模块融合。这个做法是借鉴了23年ICCV的一篇与语义分割结合的低光工作:Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement。 IFT源于base work的CPT。但是base work的CPT是将低质量图作为参考,而本文章是把ground-truth作为参考。- 发现
codebook两阶段输入的数据分布不一致,提出代码本数据偏移机制。这是较base work优秀的地方。
所以很明显,我们不应该是将别的领域的东西套过来到本领域去用,而是把自己领域的东西尽可能往别的领域靠、结合,才是更好的。要针对别的领域的工作,提出一个基于本领域的改进。
不足
- 极其依赖
ground-truth和reference。codebook的训练依赖high-quality图像进行重建不说,IFT需要一张正常光照的图作为参考。训练时期,IFT尚且可以。然而测试如果再依赖一张正常光照的图像作为reference,那就没有什么应用意义。虽然通过这种方式能够实现光照恢复动态化,但缺点也很明显。 - 解决
codebook的数据偏移问题过于粗糙,引入可学习的codebook shift增加了训练的困难。
2023 CVPR Learning a Simple Low-light Image Enhancer from Paired Low-light Instances(PairLIE)
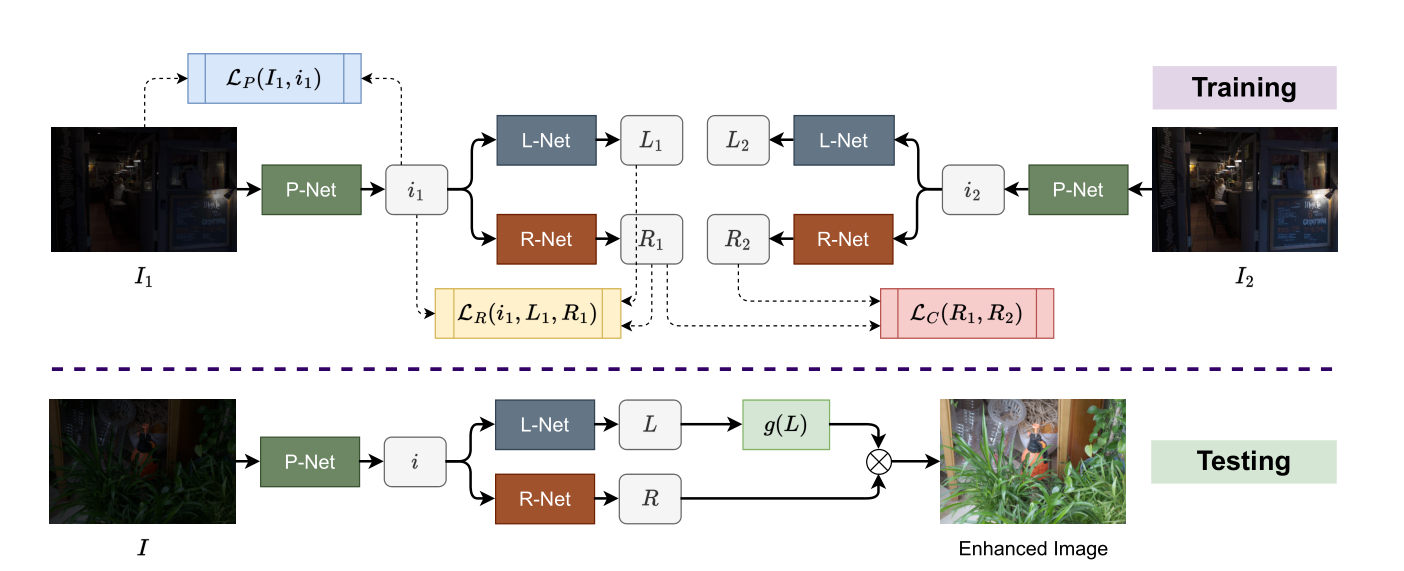
贡献
- 使用两张低光的图片,结合
Retinex理论,实现不需要额外设计手工先验的无监督低光增强。 - 在使用
Retinex分解前,使用一个映射网络有效增强分解准确率。
创新
- 将超分辨率中多图像辅助修复单图像的做法引入到低光照增强领域中,为多图像辅助修复单图像提供了低光照增强的做法。
不足
- 训练阶段,两张低光图经过
L-Net得到的结果并未充分利用。 - 这个工作更重要的意义在于,将多图像的信息辅助单图像的恢复。然而作者的做法是,多引入图片就设计一个新的,与待恢复图像相同的网络架构,即L-Net,R-Net和P-Net。倘若扩展到更多图像,不可能再同样为每一张新引入的图片设计一整套网络。因此这种做法限制了多图像的信息辅助单图像的恢复,局限于双图像。
- 推理阶段,
L-Net估计得到的L只进行一个指数变换,得到$ L^\lambda $就作为提亮后的光照,这种做法能否优化?R-Net的输出R并未经过任何处理,是否影响了性能的上限?
2024 DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement(DI-Retinex)
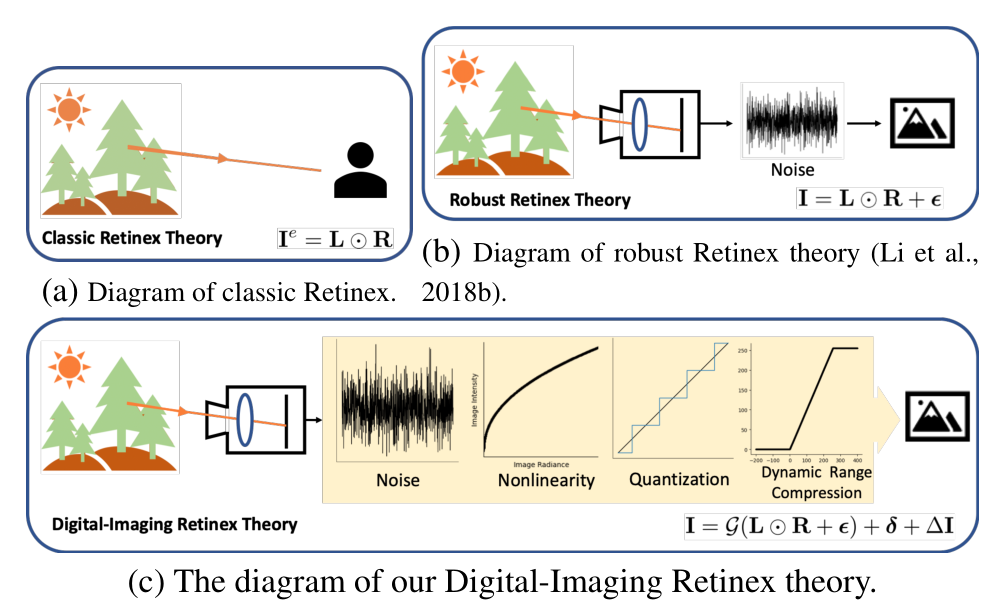
贡献
- 指出经典的
Retinex理论存在缺乏考虑噪声的问题,提出了一个新的适用于数码成像的Retinex理论DI-Retinex。 - 根据
DI-Retinex理论,重新规定了光照提亮的范式。范式中的偏置项即为经典Retinex理论未考虑到的缺陷。 - 为
DI-Retinex理论设计了两个损失,分别是将正常光照退化为低光图像的反向退化损失以及噪声的方差抑制损失。
创新
- 相对于传统的
Retinex理论以及改良版本的Retinex理论,提出的DI-Retinex理论考虑更加全面。
不足
(暂时未有)
2024 CVPR Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
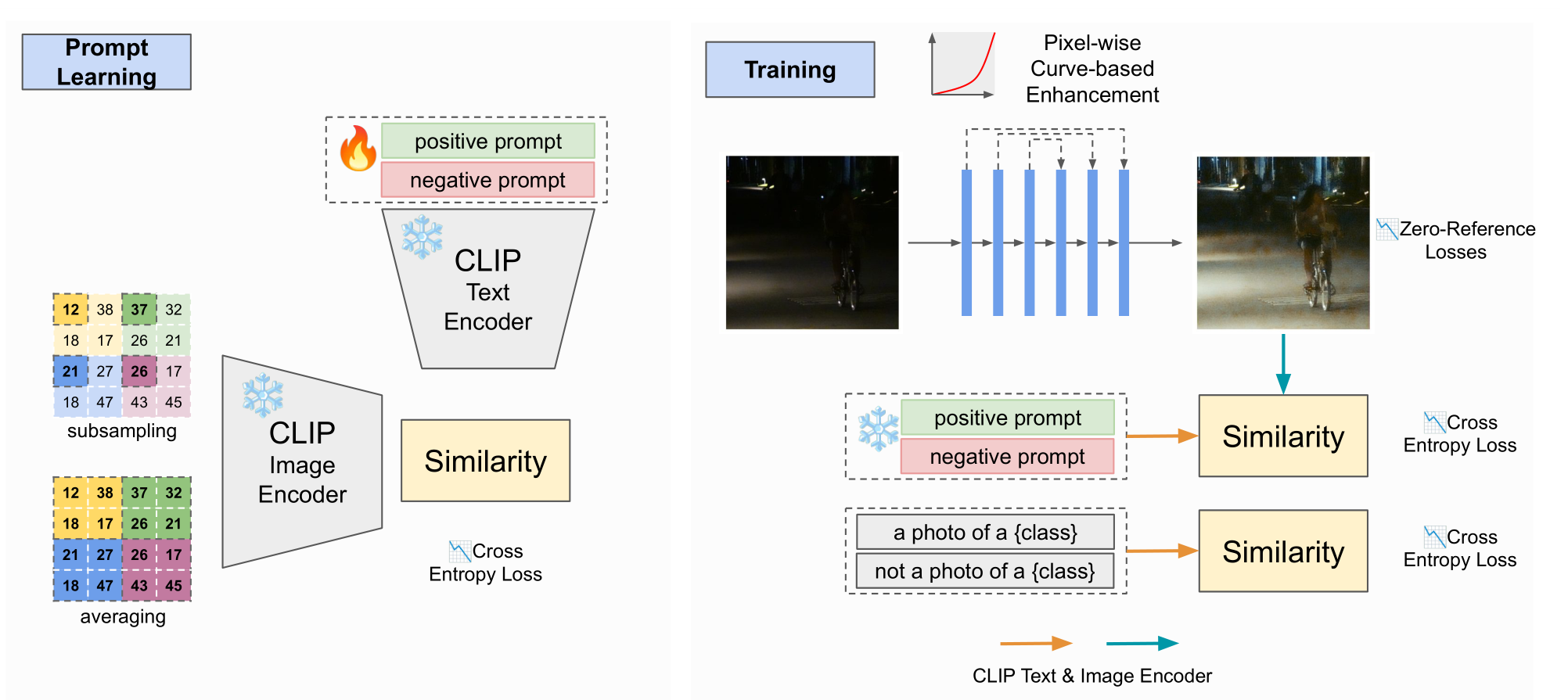
前身工作是
2023 ICCV Iterative Prompt Learning for Unsupervised Backlit Image Enhancement
存疑
- 在
prompt learning阶段要训练positive prompt和negative prompt,这两个prompt是怎么初始化的?形式是怎么样的? - 在
training阶段,使用曲线估计提亮后面的部分没看明白。
2024 GLARE: Low Light Image Enhancement via Generative Latent Feature based Codebook Retrieval(GLARE)
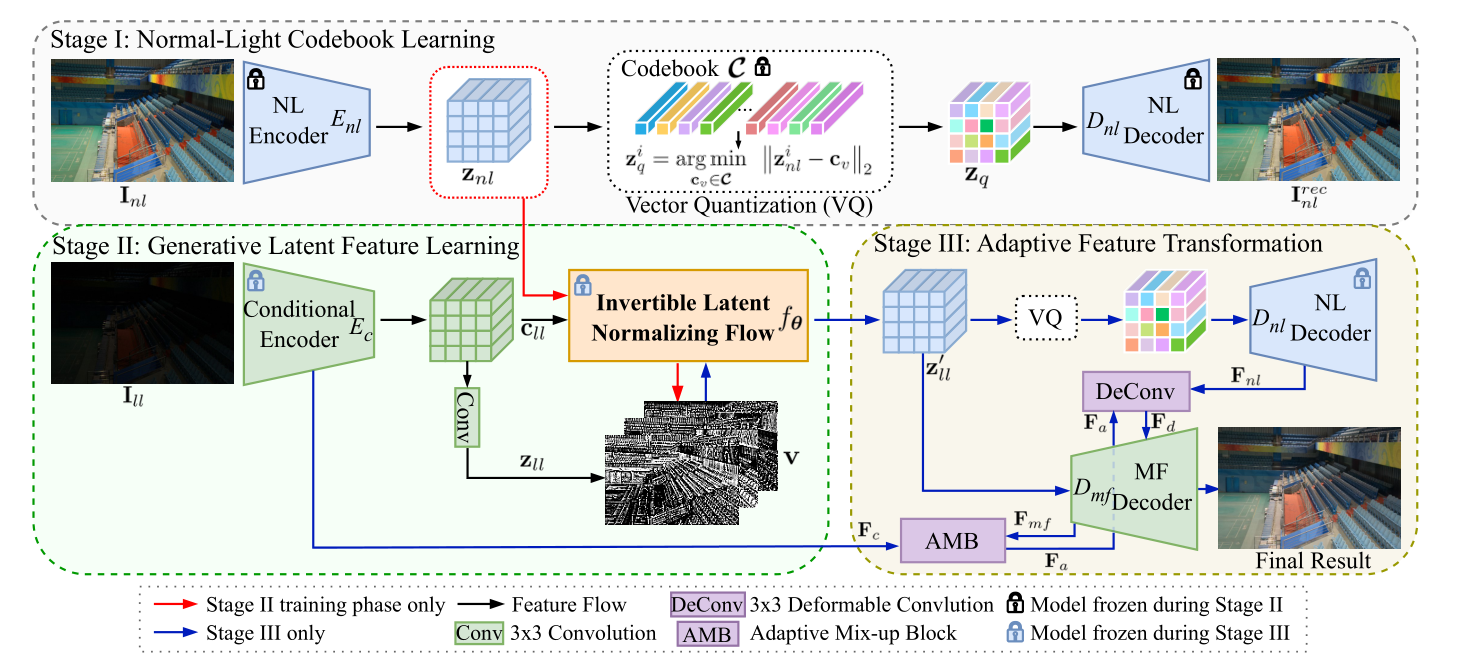
贡献
- 第一个将
codebook引入低光照图像增强领域的工作。将预训练的VQGAN进行微调以更适合低光照图像增强背景。 - 为了解决
codebook难题之阶段前后数据分布不一致,提出一个逆向潜特征正则流(Invertible Latent Normalizing Flow)的操作,将低光特征经过转换,逼近正常光照的特征,以更加适合codebook适用的数据分布。 - 为了解决
codebook难题之纹理缺失,提出一个双译码器架构实现将先前Encoder编码的特征与codebook检索出来的特征融合。
创新
- 第一篇将
codebook引入低光的工作。 - 逆向潜特征正则流(
Invertible Latent Normalizing Flow)是本文的亮点,实现了数据分布的近似转换,效率很高。 - 在双译码器端,使用一个特征适应转换模块通过调整参数实现
encoder流向decoder数据的控制,我的理解是和codeformer差不多。
不足
codebook的工作,都有泛化性相对不足的缺点。在推理阶段,codebook是在训练集上训练的,得到的是训练集的先验知识,在后续与测试集low-quality特征融合。因此需要从codebook得到知识后,需要有进一步优化操作。
2023 ICCV Implicit Neural Representation for Cooperative Low-light Image Enhancement(NeRco)
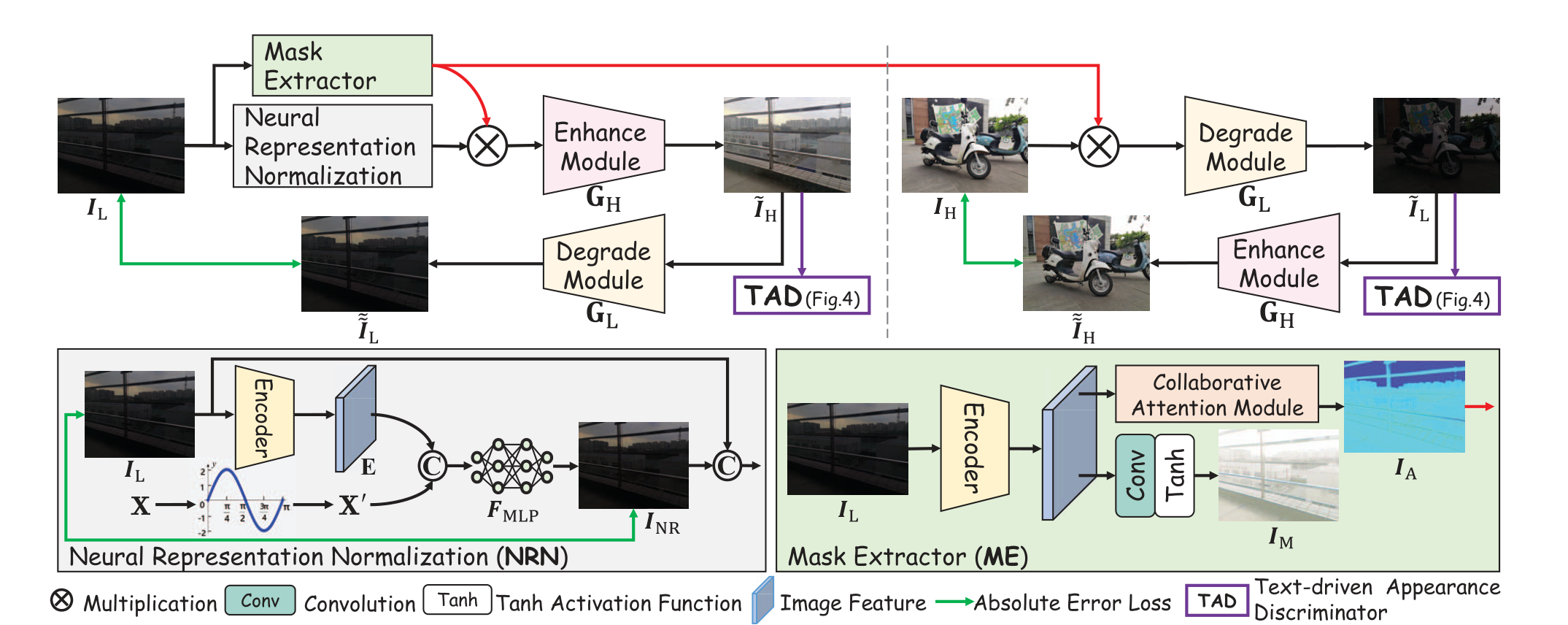
这次我们先只看这个工作的
NRN部分,也就是Neural Representation Normalization。
贡献
- 将隐式神经表征
Implicit Neural Representation第一次引入到低光照图像增强领域中。
创新
- 将隐式神经表征与低光背景很好地结合,并且解释了为何能实现去噪。
存疑
- 对隐式神经表征了解还不够多,应该往这个领域多研究研究。
2024 CVPR ZERO-IG: Zero-Shot Illumination-Guided Joint Denoising and Adaptive Enhancement for Low-Light Images(Zero-IG)
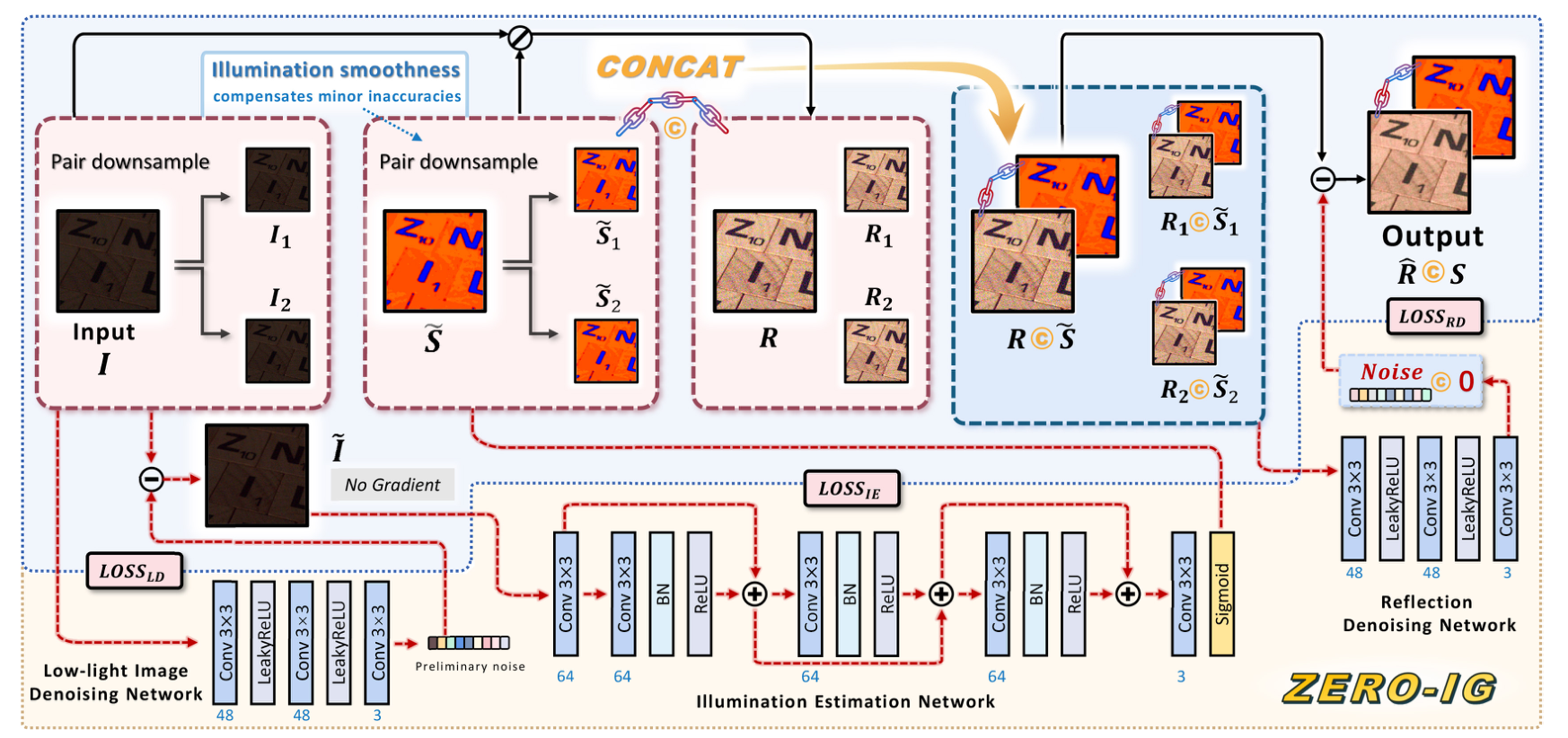
贡献:
- 重新思考
Retinex的理论,认为光照的平滑性能消除光照的噪声毛刺,所以对一个经过去噪后的低光图像提取的照度能近似正常光照下的照度。 - 将
Noise2Noise的思想引入到低光照图像增强领域,与Retinex理论很好地结合。 - 将正常光照的照度与带噪声的反射量拼接,然后使用
Noise2Noise的方式去噪。在过程中用损失约束光照全程一致,可以是网络更加关注于反射量的去噪。另外,与光照拼接,能够引导网络在去噪时关注哪些区域需要提亮,哪些区域需要抑制光照。所以,这较单纯用带噪声的反射量去噪更加有效。
创新:
- 借鉴
Noise2Noise思想,将噪声图下采样为两张图片,并彼此构建自监督的方式,避免了对配对数据集的依赖,也无需学习特定噪声分布即可应用在低光任务,实现zero-shot无监督。 - 在为反射去噪时,将光照与反射进行拼接,网络学习过程保持光照不变,使得网络更加关注对反射的去噪,这大大提高了去噪的效果。
You Only Need One Color Space: An Efficient Network for Low-light Image Enhancement
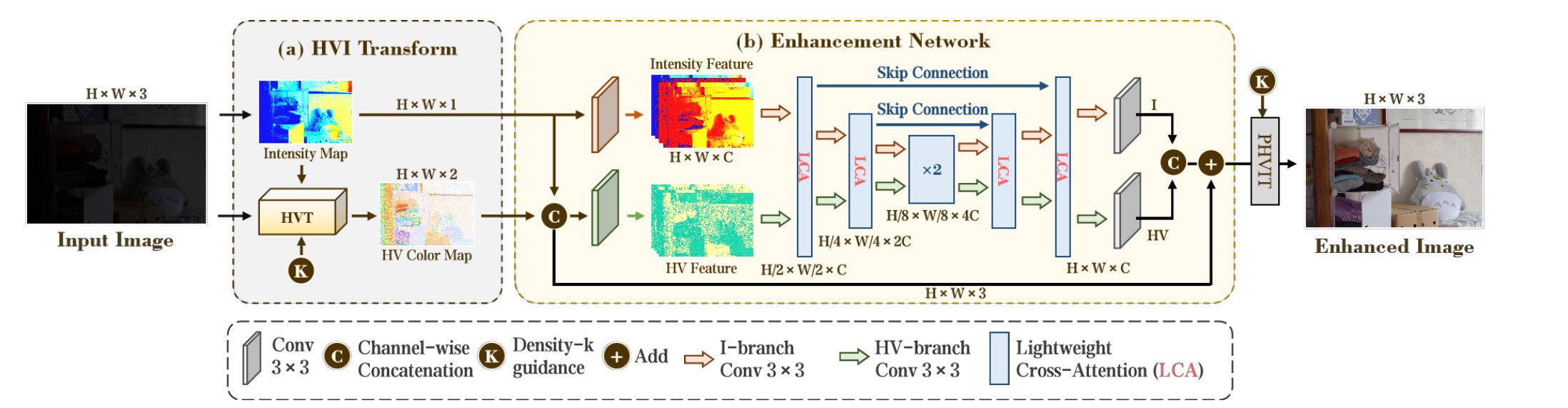
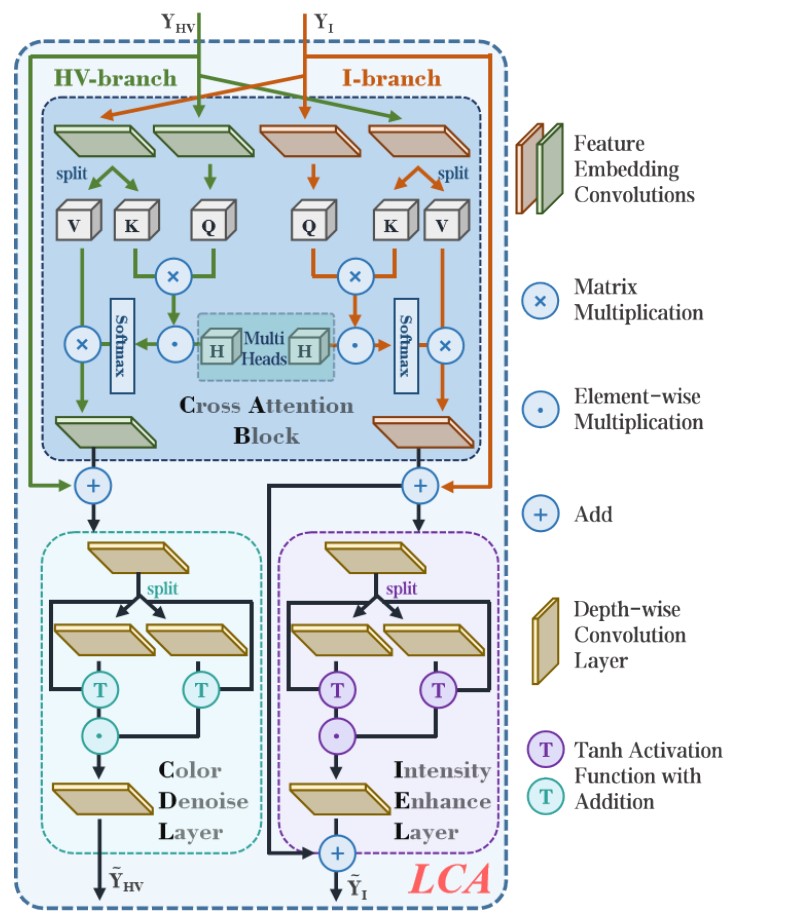
贡献:
- 为了解决传统
sRGB色彩空间存在的颜色与亮度存在的耦合问题,以及从sRGB色彩空间转换到HSV空间存在的,由于一对多映射导致信息丢失问题,本文提出了一个全新的HVI色彩空间。通过引入三个可学习的参数和一个可学习的函数提升HVI色彩空间的稳定性,同时解决了一对多映射导致的信息丢失问题。 - 将
HVI空间的图像特征分解为HV颜色特征和I强度特征,专门设计一个双支网络分别处理这两个信息。 - 提出了一个基于交叉注意力的模块
LCA,促进HV特征和I强度特征的信息交互。
创新:
- 提出了一个全新的,更稳定的,可学习的色彩空间
HVI。 - 为强度特征I和颜色特征
HV专门设计了一个双分支网络,并用交叉注意力为两个特征信息建立交互。
Image Dehazing
2023 CVPR RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors
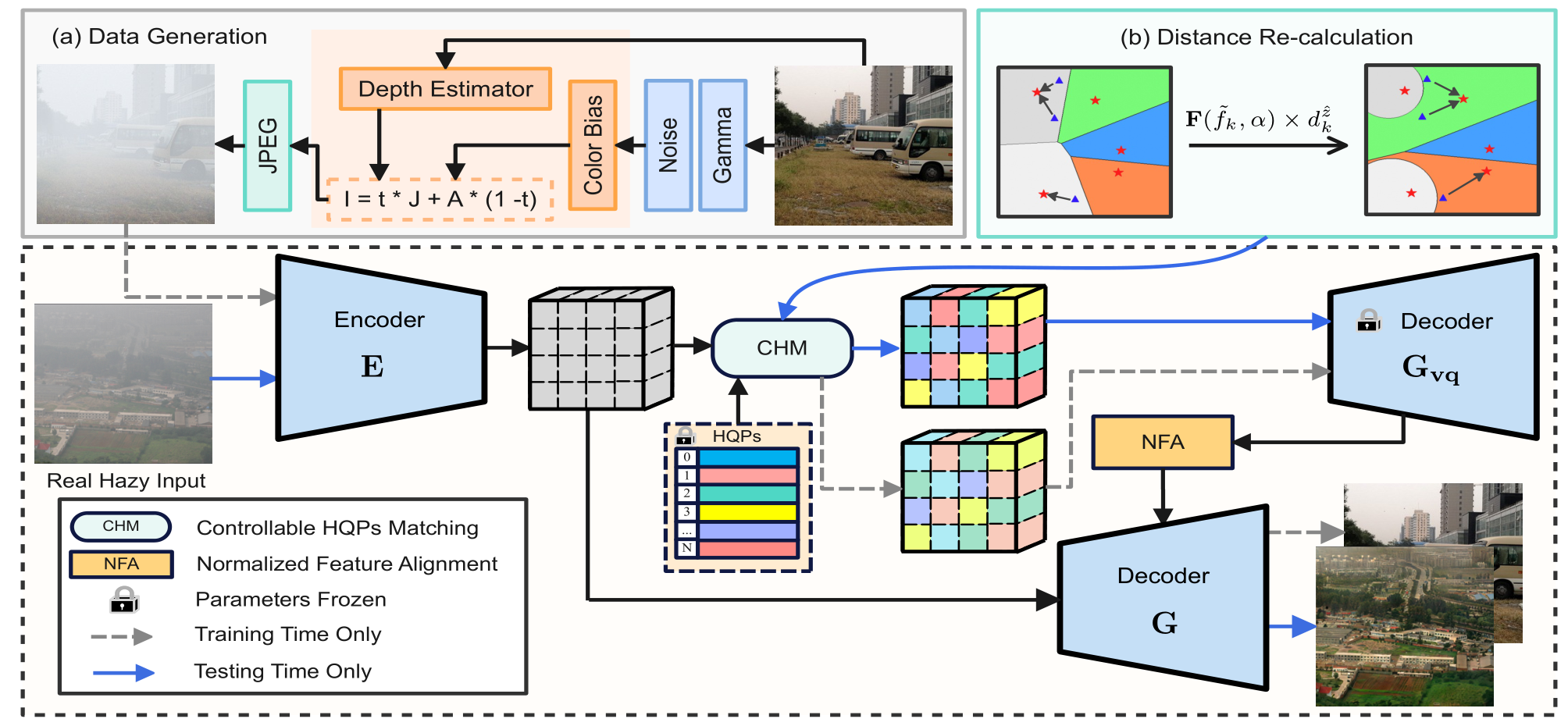
贡献
- 第一个将
codebook方法引入到去雾领域的工作。 - 设计了一个可控匹配机制
CHM替代最近邻匹配机制。具体来说,在最近邻匹配公式内的欧氏距离前乘以权重,增强匹配的效果。权重是一个自然指数,以系数a与f乘积为底。系数a通过最小化codebook特征与encoder输出特征的KL散度得到。系数f是codebook激活频率与encoder激活频率的差值(说实话论文中这个什么激活频率没交代是怎么得到的,没看明白,大概理解就是codebook与encoder的特征距离) - 设计一个双译码器,通过一个归一化特征匹配
NFA模块,将第一个译码器$ G_{vq} $的输出与encoder的输出进行特征融合。
创新
- 可控匹配机制
CHM改良了最近邻匹配机制,减轻数据分布偏差的问题。
不足
- 在可控匹配机制
CHM的实现上面,前面提到,通过乘以一个指数权重改良最近邻匹配,这个指数以两个系数乘积为底,第二个系数f,论文交代十分模糊,称为codebook激活频率差,我理解是两个数据分布的距离。在代码中也不详细,f通过一个预训练数据给出,预训练也不知道如何训练得到的。
Vision Prompt Learning
2024 Towards Effective Multiple-in-One Image Restoration: A Sequential and Prompt Learning Strategy(MiOIR)
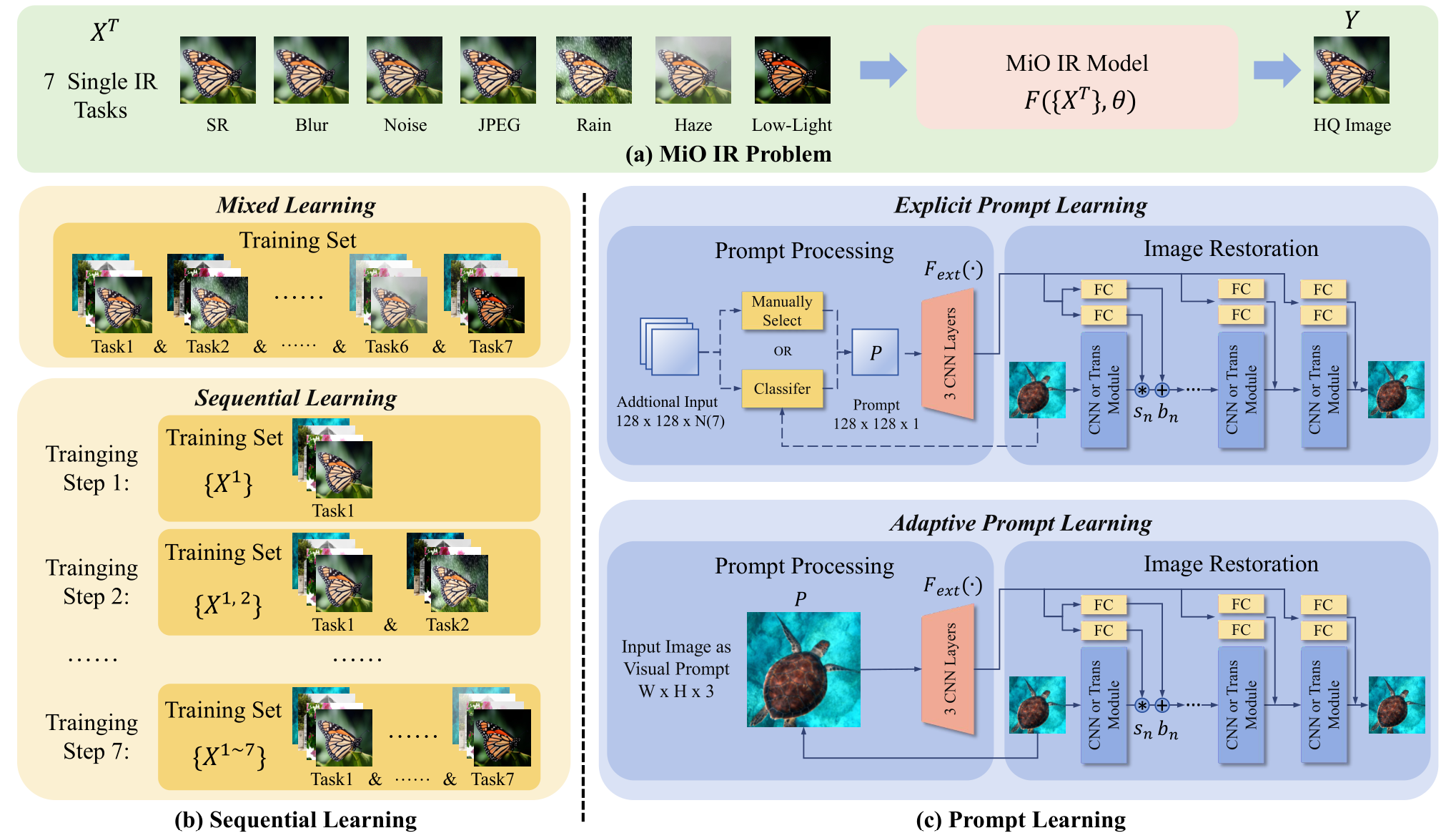
贡献
- 指出
all-in-one模型的问题:考虑的退化任务少;每一次训练只在一个特定的退化任务数据集上训练,有可能导致灾难性遗忘。提出序列学习,每次训练的数据,是上次训练的数据与新特定退化类型数据的叠加,有效应对灾难性遗忘。 - 使用两种极端的提示学习方法,帮助模型识别特定退化任务,分别是精确提示学习与自适应提示学习。
- 精确提示学习:通过预先训练提示,提示分类器,在下一阶段通过输入的退化图片筛选出适合的提示,引导特定退化任务的图像恢复。
- 自适应提示学习:通过输入的退化图片经过卷积处理得到提示信息,引导特定退化任务的恢复。
创新
- 第一次将序列学习引入到图像恢复领域。
不足
- 个人认为,自适应提示学习不能算作提示学习,更像是特征融合。
Blind Face Restoration
2022 NeurIPS Towards Robust Blind Face Restoration with Codebook Lookup Transformer(CodeFormer)
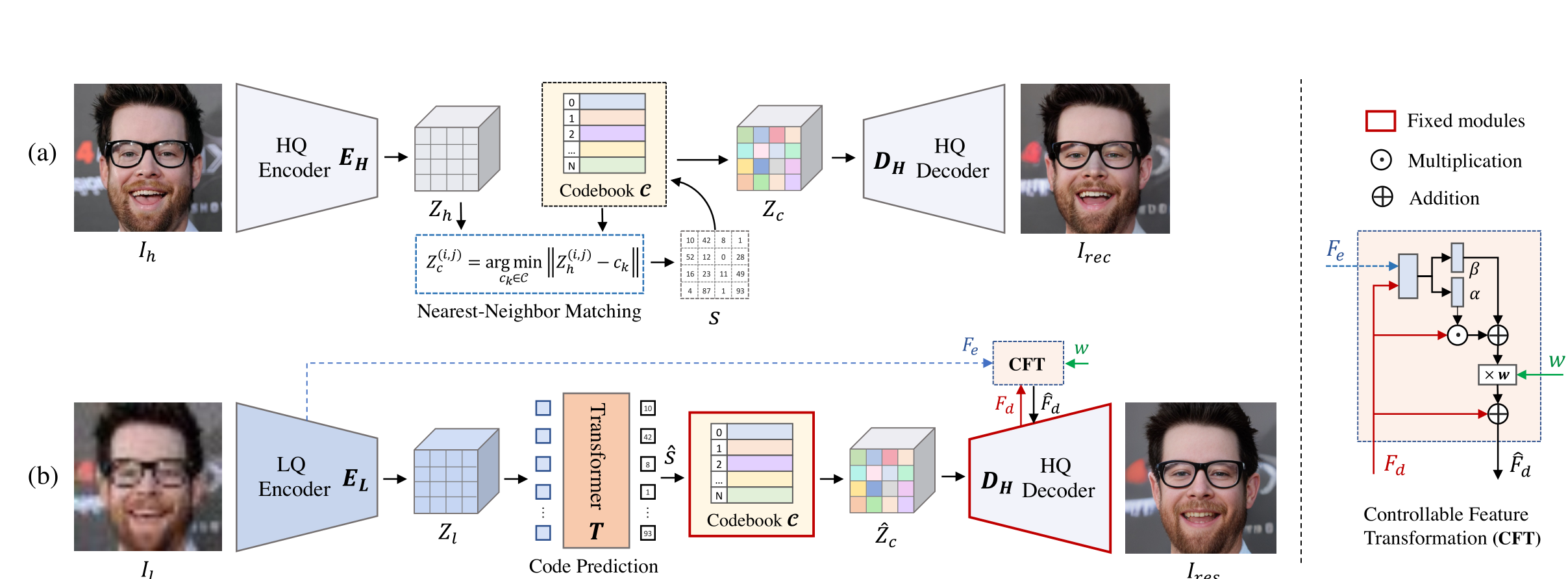
贡献
- 将
codebook引入到人脸修复领域中。 - 指出
codebook索引方式即最近邻特征匹配方法应用到图像恢复领域的不足在于,输入的Low-Quality图像因为各种类型的退化严重导致Low-Quality与codebook的数据分布严重不匹配,进而造成了codebook检索的困难。因此,为了能够更好地进行codebook的检索,使用Transformer进行codebook的检索,提高检索精确度。 - 如果仅仅将
codebook提取出来的特征进行解码,由于codebook是从其他数据集上训练得来的,因此解码得到的特征与当前数据集的GT会有很大差异,所以有必要将输入与codebook的特征进行融合,以得到一个质量更优于Low-Quality,数据分布更接近High-Quality的图片。进一步,引入一个可控的特征转换器CFT,通过一个人为设置的超参数w,实现Encoder到Decoder数据流的控制,即实现可控式的特征融合。
创新
- 将
codebook引入到人脸修复领域。 - 提出最近邻特征匹配在图像恢复的不足,为未来的工作提供了很好的指引。
- 设计了一个可控的特征融合器,进一步弥补了
codebook的不足。
不足
- 通过单一的
Transformer块叠加进行codebook索引,造成索引耗时长的问题。
Image Derain
2024 CVPR Bidirectional Multi-Scale Implicit Neural Representations for Image Deraining
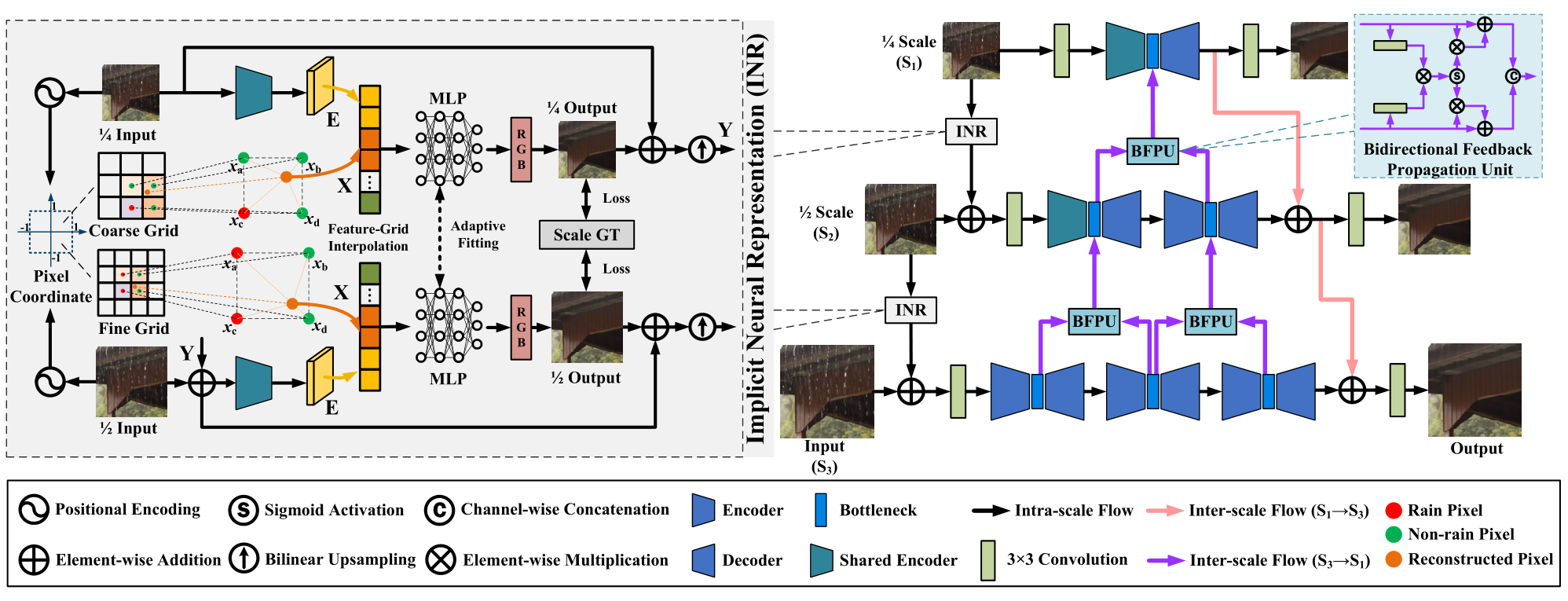
这里先主要研究前面的
Implicit Neural Representation部分。
贡献
- 将隐式神经表征第一次引入图像去雨领域中,以更好地帮助模型学习普遍雨纹退化特征进行退化的去除。
- 将隐式神经表征与多尺度网络结合,能够在多尺度信息流动中进行退化的去除。
创新
- 在每个尺度的网络前引入
Implicit Neural Representation去除雨纹,形成一个在尺度上的级联Implicit Neural Representation结构。
不足
(暂时未知)
Image Denoise
2023 CVPR Zero-Shot Noise2Noise: Efficient Image Denoising without any Data(ZS-N2N)
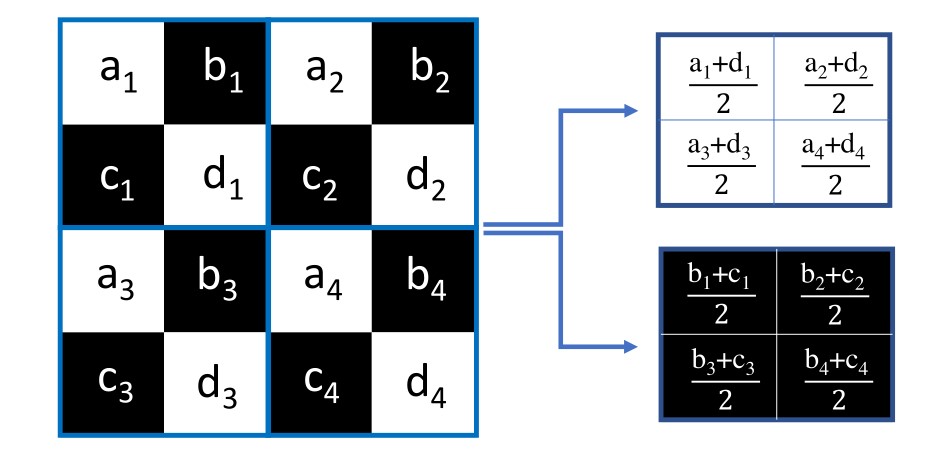
Contributions:
- They offered a downsampling-based unsupervised method. They downsampled the noisy image into two patches by using a special method at the pixel-wise level , and subsequently used two-layer convolution kernels to process the two patches.
- Mapping between noisy patches can be equivalent to denoising the input image, where a consistency loss is applied to constrain the mapping process.
- The two patches were considered as similar as possible, so there was a residual loss applied to the mapping process.
Innovations:
- By integrating the Noise2Nosie and Neighbour2Neighbour methods, the paper offered a unsupervised learning paradigm.
- It was very light-weight.
2024 CVPR Robust Image Denoising through Adversarial Frequency Mixup(AFM)
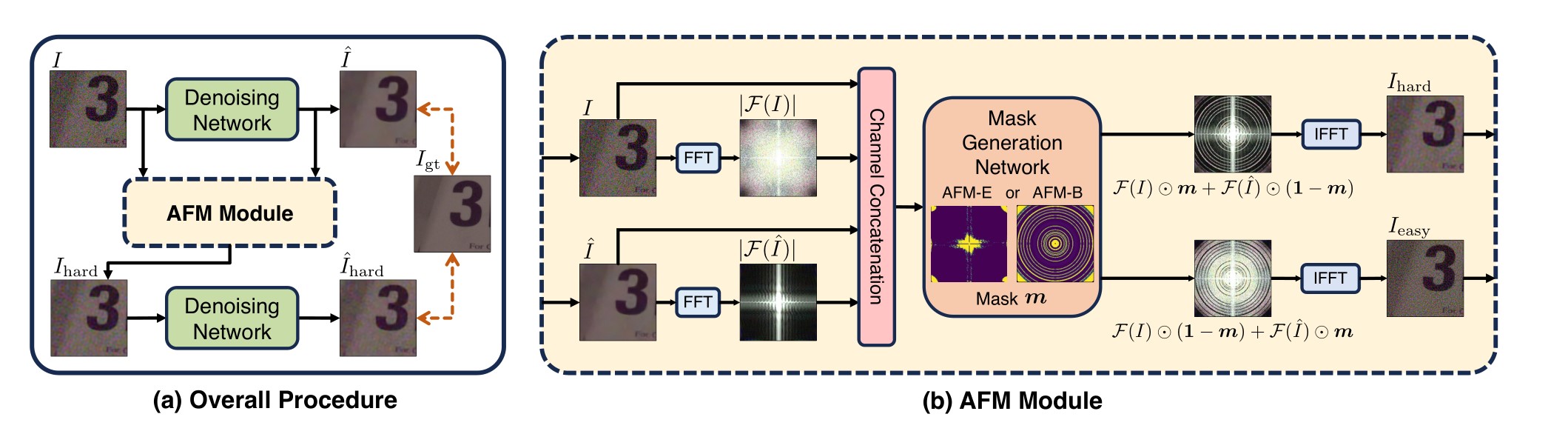
Image Enhancement
2024 CVPR Color Shift Estimation-and-Correction for Image Enhancement(CSEC)
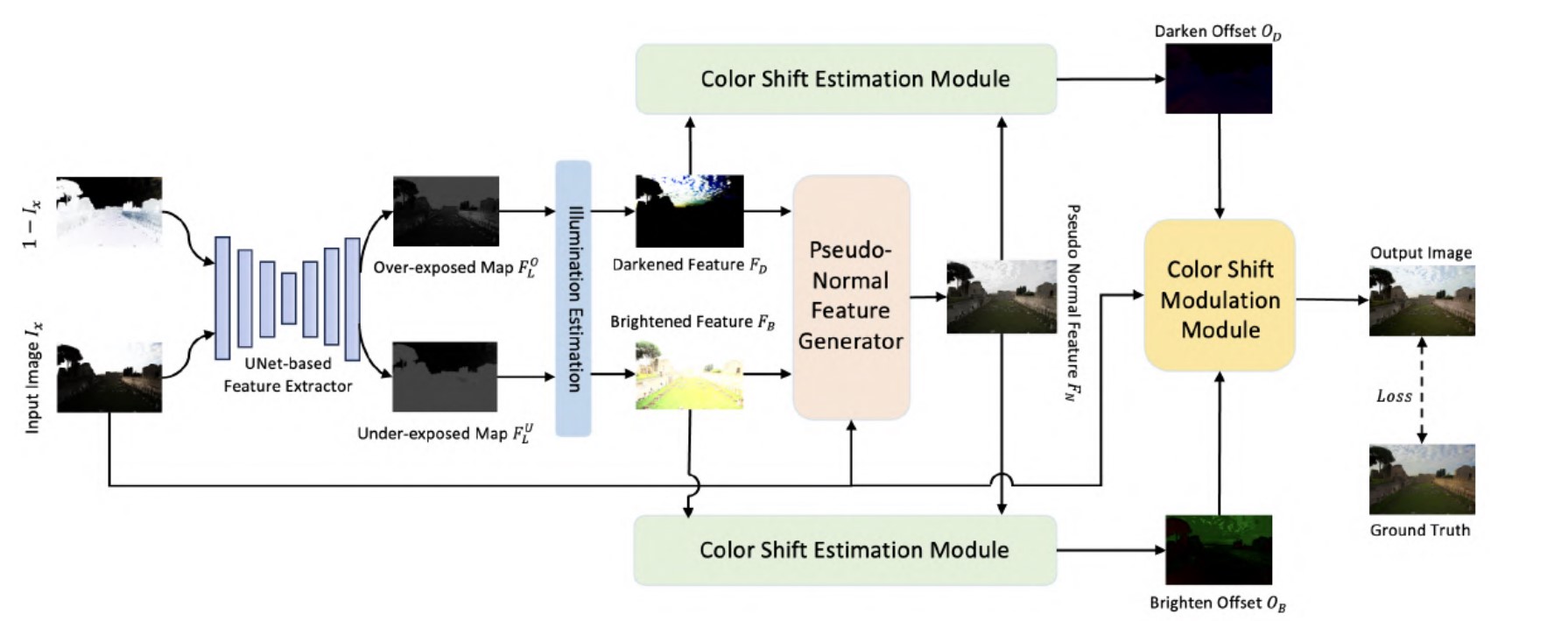
贡献:
- 通过
PCA分析发现一些图像增强数据集的图像里有欠曝光和过曝光的区域,而且这些区域的像素点特征存在明显的相反性。基于此发现,作者设计了一个能够处理一张图像同时存在过曝光和欠曝光的网络。作者利用一个基于Unet的特征提取器,提取图像中相反的两个曝光特征。 - 两种相反的曝光特征一定存在一个特征,是这两种特征的正常参照。作者为曝光程度不同的两种图像分别设计了颜色偏移估计模块,估计出颜色方面的偏移以获取正常参照的特征。鉴于可变形卷积能够为卷积核估计出图像像素点相较于卷积核的偏移,作者认为通过可变形卷积能够估计出过曝光和欠曝光相较于正常参照的颜色偏移。因此设计了
COSE模块分别估计颜色偏移。 - 为了利用估计的颜色偏移去纠正原始图像中过曝光和欠曝光的特征偏移,作者设计了一个
COMO模块,利用交叉注意力分别将原始图像的特征与过曝光颜色偏移特征和欠曝光颜色偏移特征进行建模,得到最后的增强结果图。
创新:
- 发现同一张图像中的过曝光和欠曝光存在特征相反性,并通过估计曝光的参考特征来实现同时纠正一张图像中的过曝光和欠曝光。
- 在曝光的参考特征辅助下,对过曝光和欠曝光的区域分别估计颜色偏移,借鉴可变形卷积的思想去处理颜色的特征偏移。
- 利用交叉注意力建模三个特征信息:原始图像、过曝光偏移特征、欠曝光偏移特征。
2024 CVPR Empowering Resampling Operation for Ultra-High-Definition Image Enhancement with Model-Aware Guidance(LMAR)
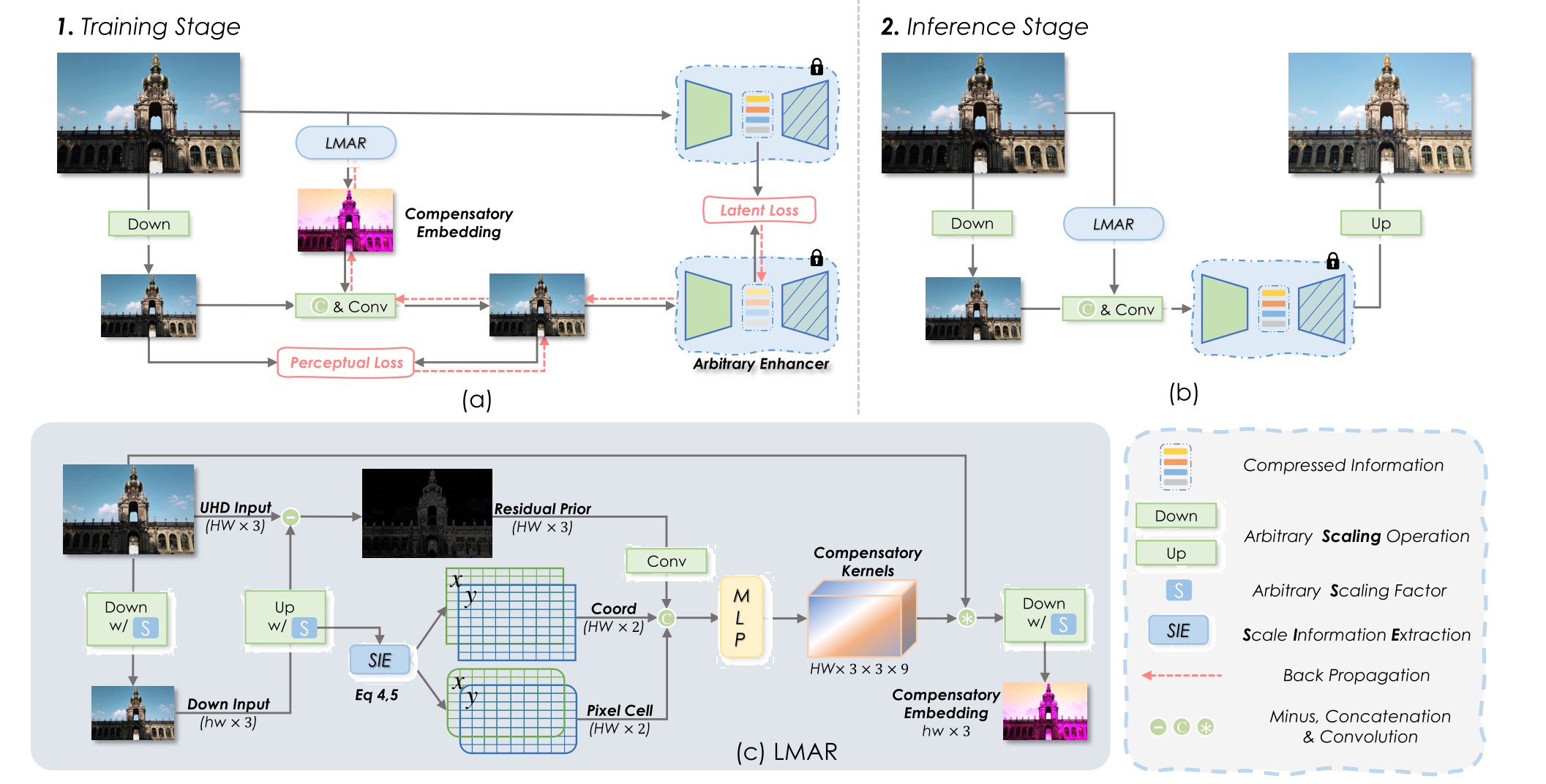
贡献:
- 这篇文章发现通过插值降低分辨率后进行增强再上采样会导致信息丢失和性能下降的现象。具体来说,有如下方面:下采样降低分辨率导致了一些高频率的信息损失;高分辨率下采样为低分辨率,两种特征分布存在差异;传统的下采样的方法与中间增强模型无关,并未考虑模型对输入的偏好(如对特定方向的边缘或低频颜色更敏感),因此无法为模型保留偏好信息。作者提出了一个叫做
LMAR的方法解决上述问题。 LMAR通过结合隐式神经表征,估计出下采样图像的补偿信息,嵌入到下采样图像中,使得低分辨率输入在中间增强模型的特征空间与原始UHD高分辨率图像的中间层特征保持一致。
创新:
- 发现下采样和重采样由于传统插值方法导致的信息丢失问题,并设计了一个基于模型感知的方法补偿损失的信息。
All-in-One Restoration
2024 LoRA-IR: Taming Low-Rank Experts for Efficient All-in-One Image Restoration(LoRA-IR)
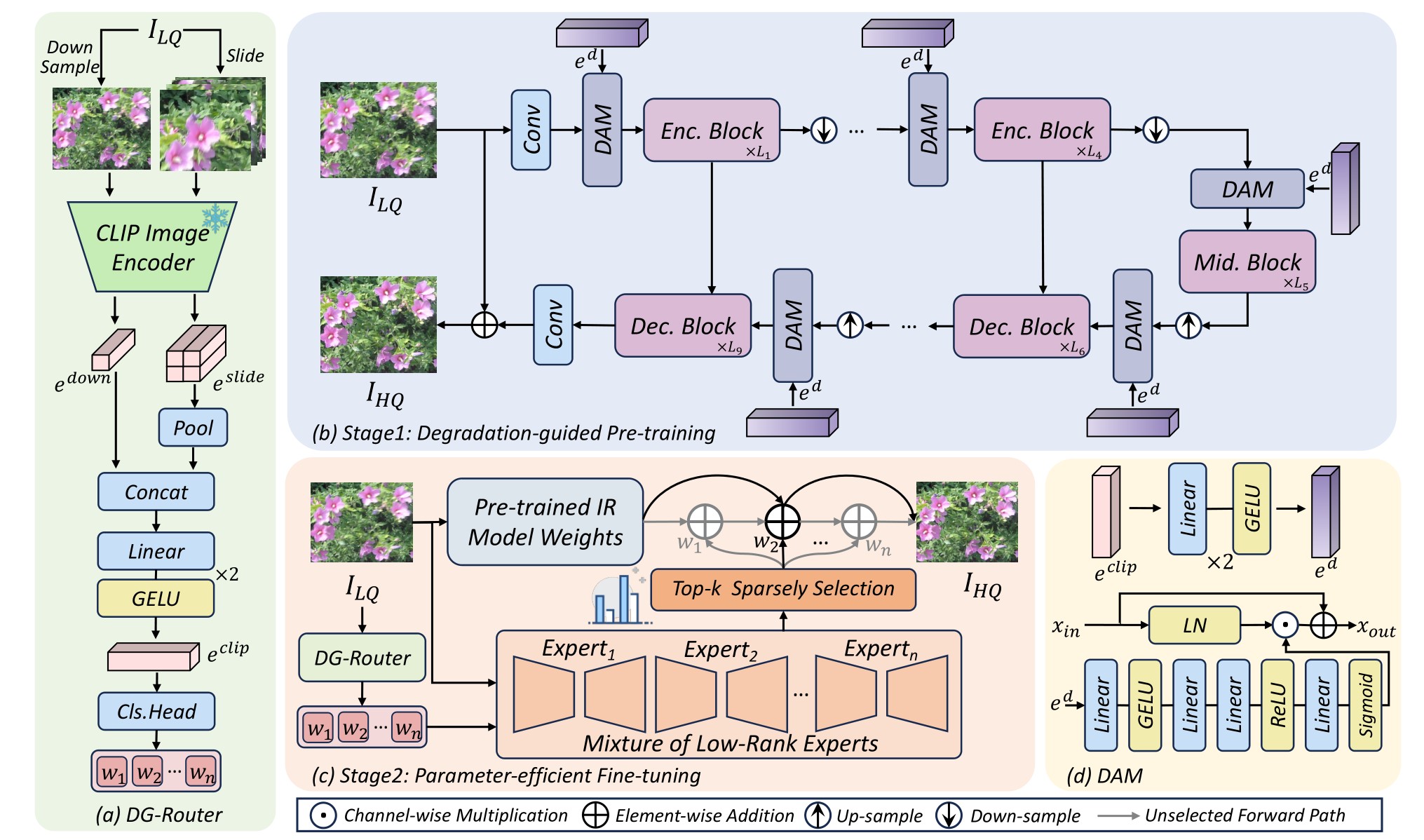
贡献:
- 针对单一退化设计专用模型的传统方法无法泛化到混合退化场景,而现有的
All-in-one模型虽然能够处理多种退化,但存在参数冗余、计算效率低、无法捕捉退化间关联性等问题。为了解决这些问题,作者引入了LoRA作为MoE的专家处理网络,并通过路由引导来选择特定的专家处理特定的退化。 - 为了针对图像选择特定的专家对退化进行处理,
LoRA-IR的退化引导路由器DG-Router使用CLIP模型的强大图像表征能力,提取退化表示。其中,为了避免因下采样到CLIP特征空间时由于分辨率降低带来的信息损失问题,DG-Router通过将滑动窗口与下采样结合来解决这个问题。另外,使用MLP和池化技术融合下采样的全局信息和滑动窗口的局部信息,生成了更加鲁棒的退化表示。 - 预训练阶段,通过
DAM(基于通道注意力的退化引导自适应调节器)将退化表征信息注入到统一的恢复网络中,增强特征的退化表示使得模型获得对特定退化的感知。微调阶段,基于MoE架构,借助DG-Router生成的退化表示动态选择多个低秩专家,进一步提升模型对未知退化的泛化能力。
创新:
将
LoRA引入到图像恢复领域。通过LoRA集成到MoE的具体专家中,实现更高效的特定退化处理。借用
CLIP强大的图像表征能力获得退化表示。结合滑动窗口和下采样缓解图像分辨率降低带来的信息损失。
2024 ECCV Restoring Images in Adverse Weather Conditions via Histogram Transformer(Histoformer)
多模态
CLIP工作
2021 Learning Transferable Visual Models From Natural Language Supervision(CLIP)
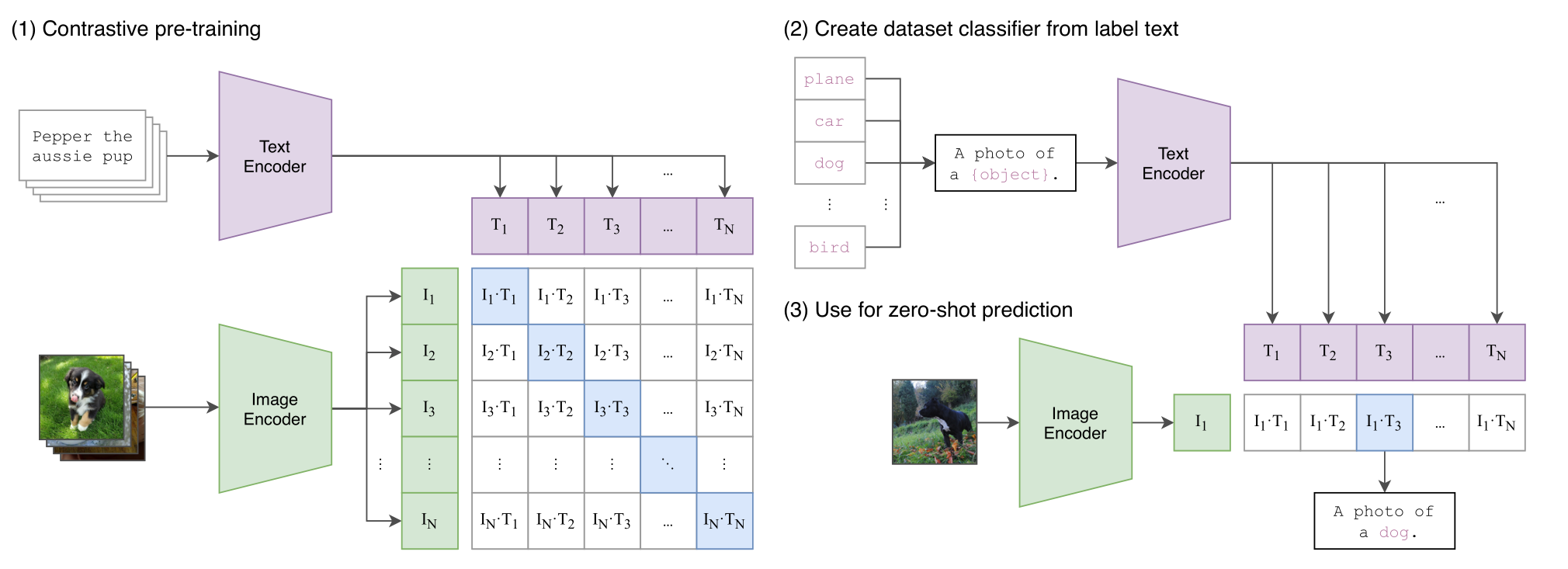
学习自朱毅老师的
CLIP逐段精读。
贡献:
- (1)通过文本和图像的对比学习,模型学习到文本-图像对的匹配关系。
- (2)能够实现通过给定一张图像,在多个文本标签中选择出与图像最相关的文本。也可以实现给定一个文本,选择最符合相关的图像。
创新:
- 实现文本与图像的多模态学习。
- 实现实现无标签限制的图像分类,也可以实现无图像限制的文本-图像配对。前者可以用于图像中的物体识别,后者可以用于文本检索图像。
CLIP对比学习训练代码:
# image_encoder - ResNet 或者 Vision Transformer
# text_encoder - CBOW 或者 Text Transformer
# I[n, h, w, c] - 图像形状
# T[n, l] - 文本形状,l是序列长度
# W_i[d_i, d_e] - 图像的线性投射矩阵
# W_t[d_t, d_e] - 文本的线性投射矩阵
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
多模态在分割的应用
2022 ICLR Language-driven semantic segmentation(LSeg)
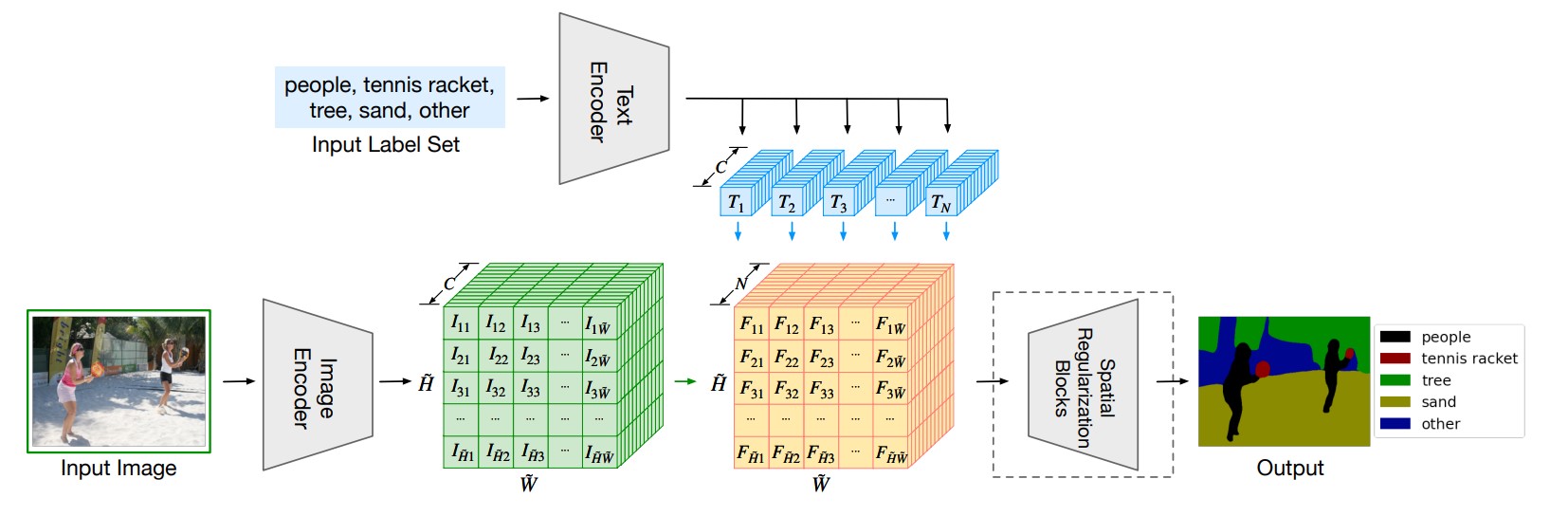
学习自朱毅老师的逐段精读。
贡献:
- 将
CLIP的原始文本编码器作为需分割的物体标签的文本编码器,以充分提取文本特征。 - 将文本特征与图像特征通过矩阵相乘融合得到多模态特征,上采样后与
Ground-truth在像素级使用cross entropy loss进行训练。 - 测试时可以实现,根据需要分割的对象的文本标签,分割特定图像的内容。
创新:
- 一篇把
CLIP模型运用到分割任务且有效果的工作。 - 采用监督学习的方式训练,而不是对比学习去训练,也是为了更好地与特定分割任务适应。
不足:
- 依然是有监督学习,目标函数不是对比学习的目标函数。
- 文本特征只是用于融合多模态特征,并没有提供监督信号。
- 依然依赖于手工标注
segmentation mask。
(可以做识别物体位置的实践)
2022 CVPR GroupViT:Semantic Segmentation Emerges from Text Supervision(GroupViT)
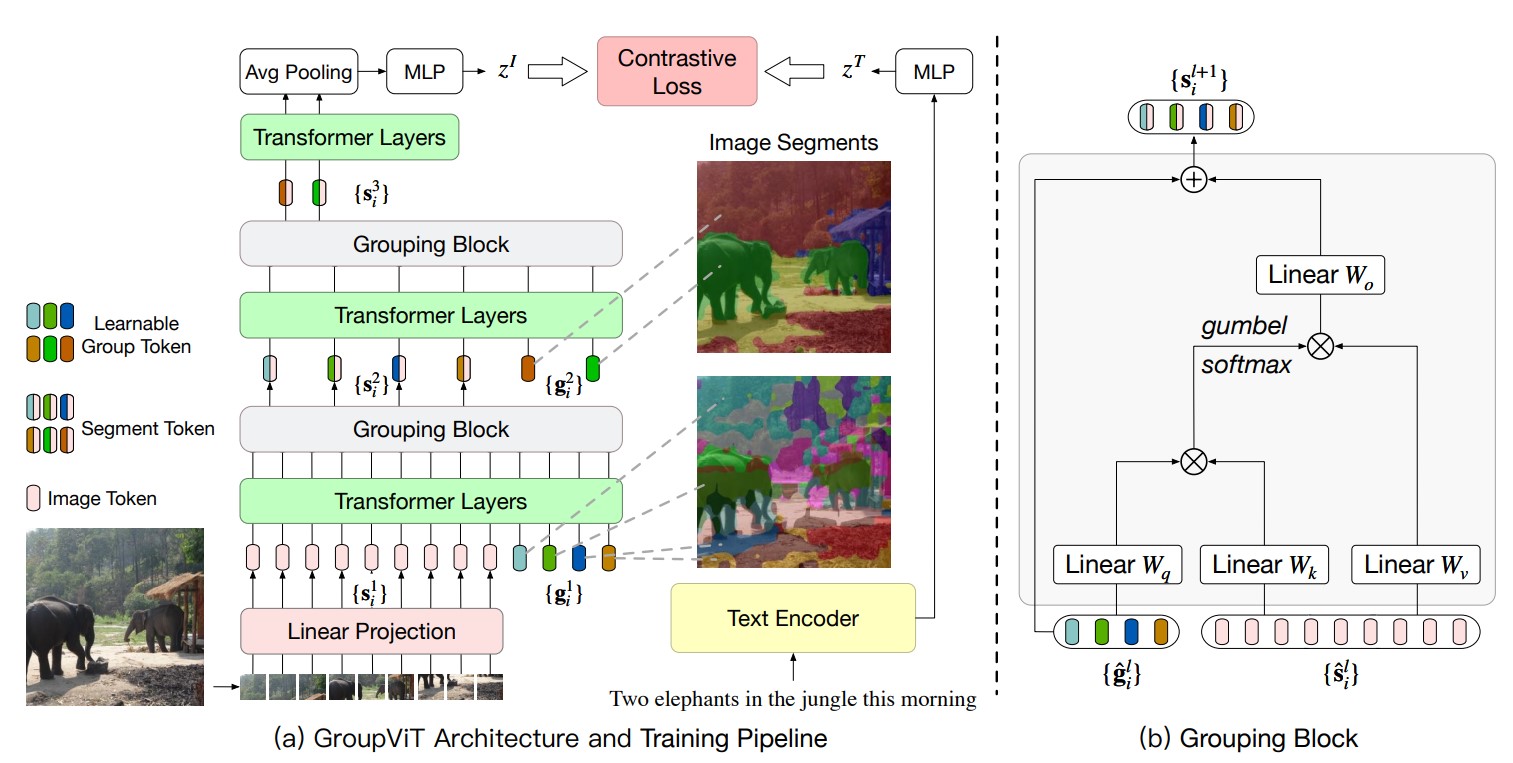
学习自朱毅老师的逐段精读。
这篇是分割采用无监督学习的思路。主要使用的是分割中的
Grouping思想。展开来讲,Grouping将图像分割做为一种聚类任务,首先在图像确定聚类中心点,然后在模型训练的过程中,不断学习聚类中心周围像素点与聚类中心的相互关系,将与聚类中心相关的像素点并入该聚类中心的Group中。
贡献:
- 使用了文本作为监督信号训练分割任务,不再依赖人工标注的图像
Ground-Truth。 - 使用
Vision Transformer作为图像编码器。在每个Transformer层的输入tokens中加入若干个group tokens,这些group tokens实际上就是预先设想的聚类中心数,也就是猜测的图像有哪些物体类别。经过多个Transformer Layer,Image tokens和这几个group tokens之间的关系被自注意力不断建模与学习。与特定聚类中心接近的image tokens,其特征也越接近该group token的特征。 - 多个
Transformer层后跟一个Grouping Block层。Grouping Block的本质是一个交叉注意力机制,将Image tokens并入所属的Group tokens。每个Grouping Block都将总tokens数降低,因此也减小了计算成本。 - 使用对比学习的方式进行训练,带监督信号的文本被编码后的特征与最后的图像
tokens特征两者交叉熵损失。
创新:
- 首先使用了文本标注分割的
Ground-Truth,不再依赖繁琐的手工标注。
不足:
- 只能分割特定数量的类别,无法分割任意数量的物体。测试时,必须指定分割物体的数目,最后得到模型输出的
tokens与文本标签进行余弦相似度的计算,确定分割物体的文本标签。 - 训练中没有侧重语义信息,仅训练出了较好的分割能力。
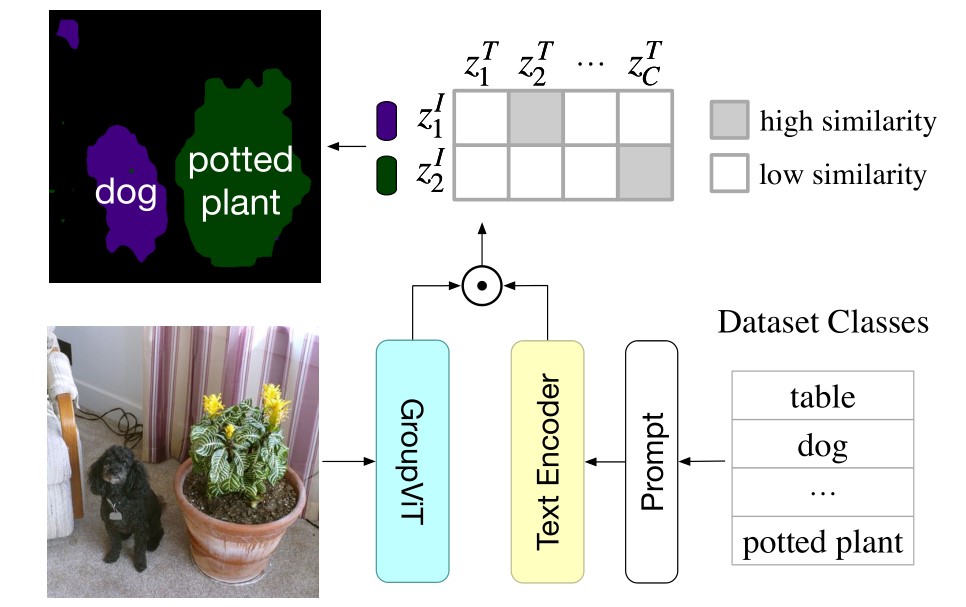
(测试时,模型输出了两个token,我们指定分割物体的文本标签有table、dog...potted plant,于是可以使用余弦相似度计算得到一个相似度矩阵。对每行取最大的值,对应的文本标签即为该token的类别)
多模态在检测的应用
2022 CVPR Grounded Language-Image Pre-training(Glip)
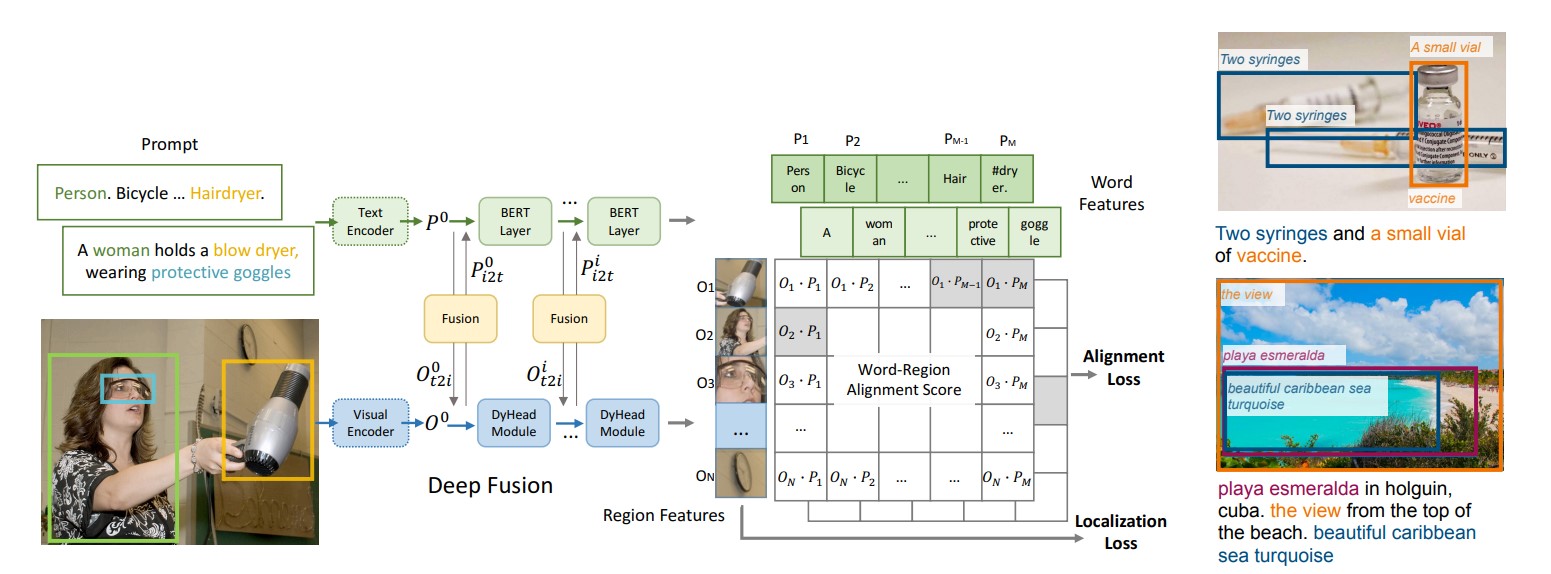
学习自朱毅老师的逐段精读。
与常规目标检测任务相关的一个任务是
Vision Grounding。具体是根据提供的文本,在图片中找到文本中出现的物体的位置。
贡献:
- 参考
CLIP范式,将图像的Bounding box的region输入图像编码器,将提供的文本输入文本编码器,最后得到每个Bounding box与单词的相似度矩阵。在相似度矩阵上与Ground-Truth的相似度矩阵求定位损失Localization Loss和分类损失Alignment Loss即可完成训练。 - 为了更加充分地学习
Bounding box和文本的Joint Feature,也就是多模态特征。在最后的特征相似度计算前,使用交叉注意力对图像特征和文本特征进行多层交互学习,即Deep Fusion。
创新:
- 使用
Deep Fusion技术以辅助学习多模态特征。 - 将
Gounding任务与目标检测任务很好地结合,并借鉴CLIP的思想做大规模数据的预训练,成功取得了很好的Zero-shot效果。
